- Home
- AI Summarizer
- Thunderbit
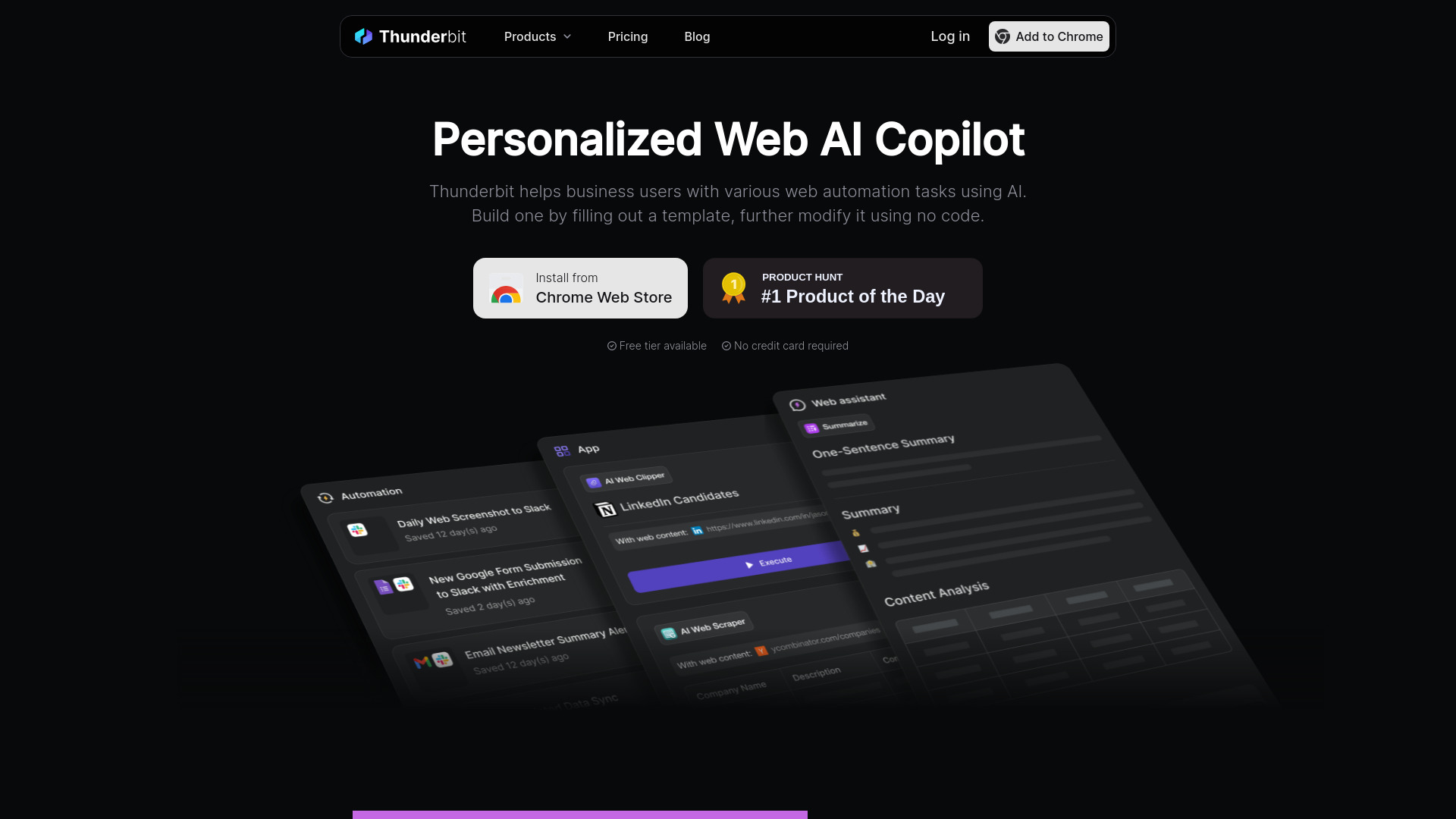
Thunderbit
Open Website-
Tool Introduction:[AI web scraper for teams—no CSS. Templates, subpages, Sheets export.]
-
Inclusion Date:Oct 28, 2025
-
Social Media & Email:

Tool Information
What is Thunderbit AI
Thunderbit AI is an AI-powered web scraping and automation platform built for business teams. It extracts structured data from websites, PDFs, documents, and images without CSS selectors or custom code. With pre-built templates and adaptive AI parsing, it automates subpage crawling, pagination, and data enrichment, then delivers results to Google Sheets, Airtable, or Notion. Sales, operations, and marketing teams use Thunderbit AI to capture contact details, build lead lists, monitor competitors, and analyze content and SEO at scale—reducing manual copy-paste and accelerating data-driven workflows.
Thunderbit AI Features
- No-code AI extraction: Pull structured data from web pages, PDFs, documents, and images without writing selectors or scripts.
- Pre-built templates: Ready-to-use templates for popular sites to launch projects quickly and consistently.
- Subpage and pagination scraping: Automatically follow internal links and page lists to capture complete datasets.
- AI-powered PDF and image parsing: Use OCR and semantic understanding to extract tables, fields, and entities from unstructured files.
- Data enrichment: Clean, normalize, and augment records to improve lead quality and analytical value.
- Easy exports: Send results directly to Google Sheets, Airtable, and Notion, or download CSV/JSON for pipelines.
- Automation: Schedule recurring runs and maintain up-to-date datasets with minimal manual effort.
- Error handling and retry: Improve coverage with automatic retries and configurable scraping settings.
- Compliance-friendly controls: Configure crawl scope and rate to align with site policies and team guidelines.
Who Is Thunderbit AI For
Thunderbit AI suits sales teams, RevOps, and SDRs building lead lists; marketing and SEO teams monitoring competitors and content performance; operations teams standardizing supplier or catalog data; agencies running recurring data collection for clients; and analysts or founders who need reliable, code-free data extraction for research and reporting.
How to Use Thunderbit AI
- Create a project and choose a pre-built template or start from scratch.
- Enter target URLs or upload PDFs/documents/images to define your data sources.
- Specify the fields you want (e.g., company, email, price, heading) using plain language.
- Configure subpage rules and pagination to follow listings, profiles, or article links.
- Preview and validate results, apply enrichment, then run the full scrape.
- Export to Google Sheets, Airtable, or Notion, or schedule recurring runs for updates.
Thunderbit AI Industry Use Cases
B2B sales: Gather company profiles and contact details from directories and websites to feed outreach workflows.
E-commerce and retail: Track competitor prices, inventory changes, and product attributes across category subpages.
Content and SEO: Collect titles, headings, metadata, and internal links to benchmark content strategy and identify gaps.
Operations and procurement: Extract SKUs and specifications from vendor PDFs to standardize catalogs.
Market research: Consolidate listings and location data from multiple sources into a single, clean dataset.
Thunderbit AI Pros and Cons
Pros:
- AI-driven, no-code setup that removes the need for CSS selectors or scripts.
- Handles websites, PDFs, documents, and images in a single workflow.
- Pre-built templates reduce setup time and improve consistency.
- Built-in subpage and pagination coverage for comprehensive datasets.
- Direct exports to Google Sheets, Airtable, and Notion streamline handoff to teams.
- Data enrichment improves accuracy and usability for leads and analysis.
Cons:
- Highly protected or frequently changing sites can reduce reliability and require adjustments.
- OCR accuracy varies with image/PDF quality, layouts, and language.
- Legal and ethical constraints apply; users must follow site terms and privacy laws.
- Edge cases and complex schemas may still need manual review or custom cleanup.
Thunderbit AI FAQs
-
Is web scraping with Thunderbit AI legal?
Legality depends on target sites, data types, and jurisdiction. Always review terms of service, robots.txt, and applicable privacy laws, and obtain permissions where required.
-
Does it work on JavaScript-heavy websites?
Thunderbit AI can process many dynamic pages and paginated lists. Results may vary on sites with heavy anti-bot measures or complex rendering.
-
Can it extract data from PDFs and images?
Yes. It uses AI/OCR to pull structured information from PDFs, scans, and images. Output quality depends on document clarity and formatting.
-
Do I need CSS selectors or coding skills?
No. You define target fields in plain language or start from pre-built templates, letting the AI handle parsing.
-
How do exports work?
You can send results directly to Google Sheets, Airtable, or Notion, or download CSV/JSON for databases and BI tools.
-
Can it follow subpages and pagination automatically?
Yes. Configure link rules to collect listings, profiles, or article pages and aggregate the data in one run.
-
How should teams handle PII and compliance?
Limit collection to necessary fields, adhere to privacy regulations (e.g., GDPR/CCPA), and ensure you have a lawful basis for processing any personal data.