Helicone
Open Website-
Tool Introduction:Open-source LLM observability: monitor, debug, trace, cost, 1-line setup.
-
Inclusion Date:Oct 31, 2025
-
Social Media & Email:




Tool Information
What is Helicone AI
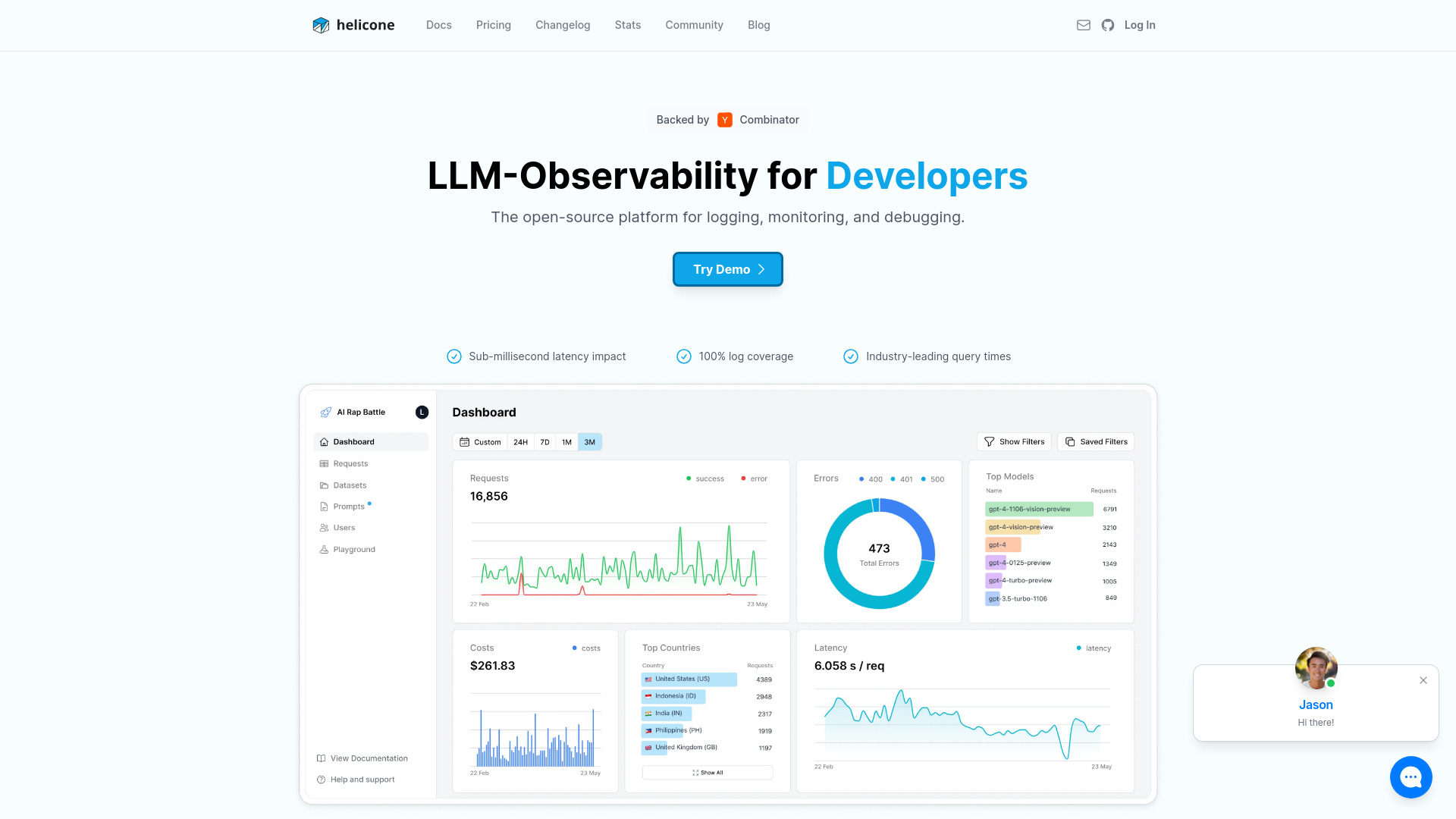
Helicone AI is an open-source LLM observability platform for monitoring, debugging, and improving production AI applications. With a simple one-line integration, it captures structured telemetry for prompts, responses, tokens, latency, errors, and costs. Teams get centralized dashboards, agent tracing, and prompt management to analyze behavior, reduce spend, and increase reliability. By turning raw LLM requests into actionable insights, Helicone helps developers ship features faster and maintain confidence in complex, agentic workflows at scale.
Main Features of Helicone AI
- One-line integration: Add a proxy or SDK to start logging requests without major code changes.
- Comprehensive monitoring: Track latency, error rates, throughput, and performance across models and routes.
- Cost and token analytics: Measure usage and costs per model, user, or endpoint to control budgets.
- Agent tracing: Visualize multi-step chains and agent spans to debug complex reasoning paths.
- Prompt management: Version, compare, and refine prompts with context-rich request histories.
- Searchable logs and filters: Quickly find problematic requests by tag, user, time window, or status.
- Privacy controls: Redact sensitive fields and manage data retention to meet compliance needs.
- Dashboards and alerts: Observe health at a glance and set alerts for anomalies or spend thresholds.
- Provider-agnostic: Works across popular LLM providers and model hosts to avoid lock-in.
- Data export: Export observability data for deeper analysis in your BI or data warehouse.
Who Can Use Helicone AI
Helicone AI is designed for AI engineers, machine learning teams, platform and DevOps engineers, product managers, and FinOps stakeholders who need visibility into LLM behavior and spend. It fits startups shipping their first AI features, enterprises operating production agents, and any team building chatbots, copilots, RAG pipelines, or content generation systems that require robust monitoring and debugging.
How to Use Helicone AI
- Sign up for the hosted service or deploy the open-source stack in your environment.
- Add the one-line proxy/SDK integration by updating your LLM base URL or client configuration.
- Tag requests with metadata (user, route, experiment) to enable granular filtering and cost attribution.
- Enable agent tracing to capture spans across tools, retrieval steps, and function calls.
- Ship your app and review dashboards, logs, and traces to monitor performance and errors.
- Iterate on prompt management using insights from traces, feedback, and cost metrics.
- Set alerts and budgets to catch anomalies early and keep production behavior within targets.
Helicone AI Use Cases
Product teams use Helicone to monitor chatbots and AI assistants in customer support. Data teams trace RAG pipelines to diagnose retrieval quality and latency spikes. SaaS platforms track token usage and costs across tenants for accurate chargebacks. Engineering teams debug multi-agent workflows in developer copilots. Regulated industries use redaction and audit-friendly logs to review model outputs while maintaining privacy controls.
Helicone AI Pricing
Helicone is open-source and can be self-hosted without license fees. A managed cloud offering is also available with tiered plans that typically include a free option for evaluation and paid tiers for higher volumes and enterprise features. For current plan details and limits, refer to the official Helicone website.
Pros and Cons of Helicone AI
Pros:
- Open-source with flexibility to self-host or use managed cloud.
- Fast, one-line integration minimizes engineering effort.
- Rich agent tracing and logs streamline debugging.
- Clear cost tracking and token analytics for FinOps.
- Provider-agnostic approach reduces vendor lock-in.
- Privacy features (redaction, retention) support compliance needs.
Cons:
- Proxy-based logging can introduce a small amount of overhead.
- Effective use may require thoughtful tagging and instrumentation.
- Self-hosting adds operational maintenance responsibilities.
- Advanced dashboards and tracing have a learning curve for new users.
FAQs about Helicone AI
-
Is Helicone AI open-source?
Yes. Helicone offers an open-source core that you can self-host, alongside a managed cloud option.
-
How does the one-line integration work?
You point your LLM client to Helicone’s proxy or add its SDK, which automatically captures request and response telemetry.
-
Which LLM providers are supported?
Helicone is provider-agnostic and works with popular LLM APIs, making it suitable for multi-model stacks.
-
Will using Helicone affect latency?
There may be minimal overhead from proxying and logging, typically outweighed by the observability benefits.
-
Can I redact sensitive data?
Yes. You can redact fields and configure retention to help meet privacy and compliance requirements.
-
Does it support agent and tool tracing?
Helicone captures spans and steps across agents, tools, and retrieval, enabling detailed debugging of complex workflows.