LlamaIndex
Open Website-
Tool Introduction:Chub AI: open GenAI platform with no-login search, plus legacy access.
-
Inclusion Date:Oct 21, 2025
-
Social Media & Email:



Tool Information
What is LlamaIndex
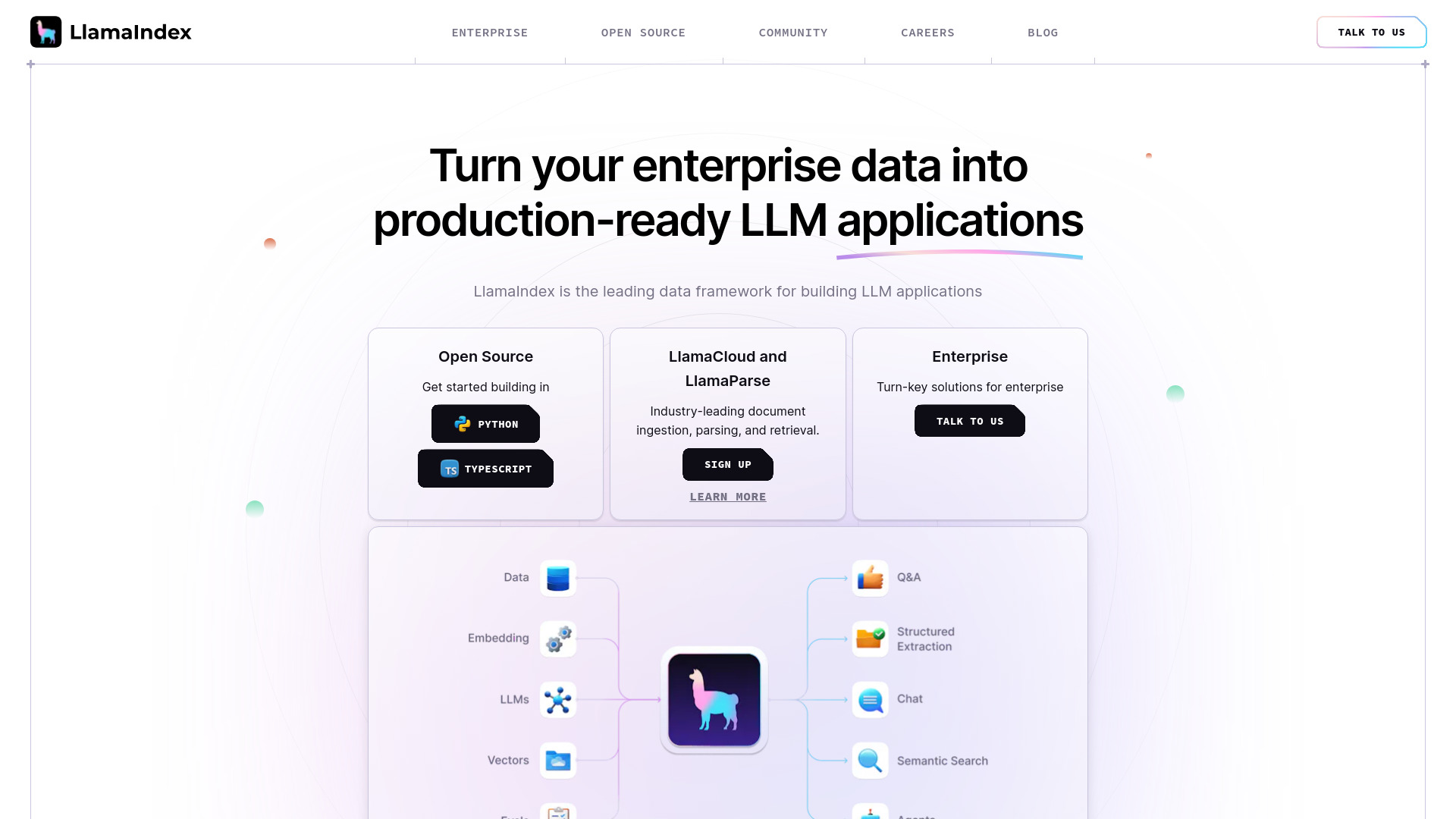
LlamaIndex is a simple, flexible framework for building knowledge assistants that connect large language models to your enterprise data. It unifies document parsing (including complex PDFs), data extraction, indexing, retrieval, and an agent framework so applications can find information, synthesize insights, generate reports, and take actions across large, messy knowledge bases. With modular connectors, query engines, and observability, teams can deliver reliable RAG and agentic workflows while keeping data control and model choice. It integrates with popular vector databases and LLM providers, supports structured outputs, and scales from prototypes to production.
LlamaIndex Key Features
- End-to-end RAG pipeline: Ingestion, indexing, retrieval, and response synthesis optimized for enterprise knowledge.
- Advanced document parsing: Robust PDF and unstructured file parsing to preserve layout, tables, and hierarchy for better retrieval.
- Data connectors: Pluggable connectors for databases, cloud storage, and SaaS sources to unify siloed content.
- Multiple index types: Vector, list, tree, and graph-style indexes to match query and data characteristics.
- Agent framework: Tool-using agents with function calling to search, plan, synthesize, and take actions across systems.
- Structured extraction: Pydantic-style schemas and validators to turn unstructured text into reliable, typed outputs.
- Reranking and hybrid search: Combine embeddings, keyword search, and rerankers for accuracy and recall.
- Observability and evaluation: Built-in tracing, metrics, and evals to measure quality, latency, and cost.
- Model and vector DB agnostic: Works with major LLMs and vector stores so you can choose the best-fit stack.
- Caching and performance controls: Incremental ingestion, chunking, and caching to keep costs and latency predictable.
- Access-aware retrieval: Use metadata and filters to respect document-level permissions in retrieval workflows.
Who Should Use LlamaIndex
LlamaIndex suits data teams, ML engineers, and software developers building retrieval-augmented generation, document question answering, and agentic workflows over enterprise data. It is well-suited for knowledge management, customer support, research and analytics, legal and compliance review, operations runbooks, and any scenario where accurate, explainable answers must be grounded in proprietary documents.
How to Use LlamaIndex
- Connect data sources: Configure connectors to files, object stores, databases, or SaaS knowledge bases.
- Parse and chunk: Use the parsing pipeline to extract text, tables, and structure; apply chunking and metadata.
- Create indexes: Build vector or graph-style indexes and store them in your preferred vector database.
- Configure retrieval: Set retrievers, filters, and rerankers; define response synthesis strategies.
- Add agents and tools: Wire functions/APIs the agent can call to search, summarize, or execute actions.
- Evaluate and observe: Run evals, inspect traces, and tune chunking, prompts, and models for quality.
- Deploy and monitor: Ship the service, monitor latency/cost, and iterate with incremental updates.
LlamaIndex Industry Use Cases
Enterprises deploy LlamaIndex to power self-serve support over product docs and tickets; financial analysts use it to extract KPIs and generate earnings summaries; legal teams run contract Q&A and clause comparison; life sciences groups synthesize literature and lab notes; operations teams build agents that read runbooks, file incident reports, and trigger workflows, all grounded in internal knowledge.
LlamaIndex Pricing
The core LlamaIndex framework is available as an open-source library. Optional managed services (such as hosted parsing and indexing) are offered with free tiers or paid plans depending on usage and support needs. Organizations can adopt the open-source stack end to end or combine it with managed components as requirements grow.
LlamaIndex Pros and Cons
Pros:
- Flexible, modular RAG and agent framework that fits varied data and workloads.
- Strong document parsing for complex PDFs and unstructured content.
- Vendor-agnostic integration with leading LLMs and vector databases.
- Built-in observability and evaluation to improve reliability.
- Scales from quick prototypes to production deployments.
Cons:
- Requires engineering effort to design good chunking, indexing, and prompts.
- Retrieval quality depends on data hygiene and metadata discipline.
- Latency and cost can grow with very large corpora without careful tuning.
- Access control and governance must be implemented and enforced by the adopter.
LlamaIndex FAQs
-
What models and vector stores does LlamaIndex support?
It integrates with major LLM providers and open-source models, and works with popular vector databases as well as in-memory/local options.
-
Can I use LlamaIndex just for RAG without agents?
Yes. You can build a pure retrieval-augmented generation stack, then optionally add agents and tools later.
-
How does LlamaIndex handle document permissions?
You can attach metadata and apply filters during retrieval to respect document-level access rules within your application.
-
Does it support structured data extraction?
Yes. Define schemas to extract fields from unstructured content and return validated, typed outputs.
-
How do I improve answer accuracy?
Invest in parsing quality, chunking strategy, richer metadata, reranking, and evaluations; iterate on prompts and model choice.