AiHubMix
Mở trang web-
Giới thiệu công cụ:Router API chuẩn OpenAI cho Gemini, Qwen; song song không giới hạn
-
Ngày thêm:2025-11-02
-
Mạng xã hội & Email:

Thông tin công cụ
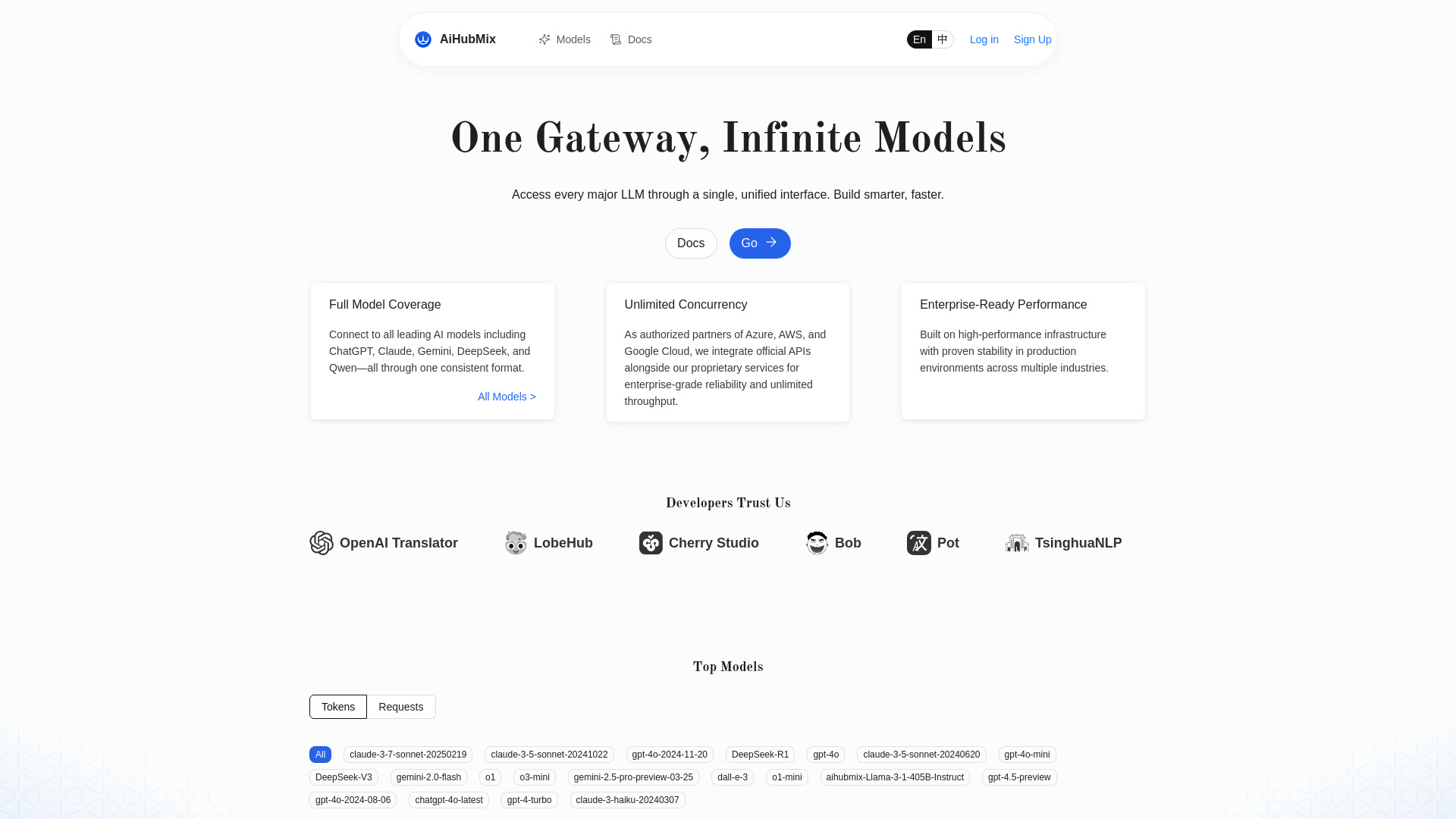
AiHubMix là gì?
AiHubMix là một LLM API router kiêm OpenAI API proxy giúp bạn truy cập và chuyển tuyến giữa nhiều mô hình AI hàng đầu như OpenAI, Google Gemini, DeepSeek, Llama, Qwen (Alibaba), Claude, Moonshot AI và Cohere qua một chuẩn API thống nhất. Thay vì tích hợp từng nhà cung cấp với các SDK khác nhau, bạn chỉ cần gọi theo chuẩn OpenAI API để sử dụng nhiều mô hình mới nhất, tối ưu chi phí và hiệu năng. AiHubMix hỗ trợ đồng thời không giới hạn, giảm độ phức tạp khi mở rộng hệ thống, hạn chế khóa chặt nhà cung cấp và rút ngắn thời gian phát triển các ứng dụng AI sinh ngữ thông minh, ổn định và dễ bảo trì.
Các tính năng chính của AiHubMix
- Chuẩn OpenAI API thống nhất: Gọi chat/completions, embeddings… qua một giao diện quen thuộc, giảm thay đổi mã nguồn.
- Tích hợp đa mô hình: Hỗ trợ OpenAI, Gemini, DeepSeek, Llama, Qwen, Claude, Moonshot AI, Cohere trong một endpoint duy nhất.
- Định tuyến thông minh: Dễ cấu hình alias, chọn mô hình theo nhu cầu tác vụ; hỗ trợ chuyển tuyến dự phòng (fallback) khi nhà cung cấp gặp lỗi.
- Cân bằng tải và đồng thời cao: Tối ưu thông lượng với khả năng unlimited concurrency, phù hợp khối lượng lớn và thời gian thực.
- Cập nhật nhanh mô hình mới: Theo kịp các phiên bản LLM mới mà không cần sửa nhiều ở phía ứng dụng.
- Tương thích SDK sẵn có: Làm việc mượt với OpenAI SDK, cURL, HTTP client phổ biến; chỉ cần đổi baseURL và khóa.
- Quy ước đặt tên linh hoạt: Hỗ trợ đặt alias/model mapping để chuyển đổi nhà cung cấp mà không ảnh hưởng luồng nghiệp vụ.
- Tối ưu chi phí/hiệu năng: Cho phép so sánh, A/B giữa các mô hình để chọn phương án cân bằng chất lượng – độ trễ – chi phí.
Đối tượng phù hợp với AiHubMix
AiHubMix phù hợp với đội ngũ phát triển sản phẩm AI, startup cần thử nghiệm nhanh nhiều mô hình, doanh nghiệp muốn mở rộng hạ tầng trợ lý ảo/chatbot, nhóm dữ liệu triển khai RAG/tóm tắt/tri thức nội bộ, cũng như các nền tảng cần ổn định ở tải cao. Bất kỳ trường hợp nào muốn giảm rủi ro phụ thuộc một nhà cung cấp, chuẩn hóa cách gọi API, và tăng tốc ra mắt tính năng AI đều hưởng lợi từ AiHubMix.
Cách sử dụng AiHubMix
- Đăng ký và lấy khóa truy cập (API key) cùng baseURL của AiHubMix.
- Cấu hình khóa nhà cung cấp (OpenAI, Gemini, DeepSeek, v.v.) nếu hệ thống yêu cầu để ủy quyền định tuyến.
- Trong ứng dụng, thay baseURL của OpenAI API bằng địa chỉ AiHubMix; giữ nguyên OpenAI SDK hoặc HTTP client.
- Chọn model hoặc alias tương ứng (ví dụ: gpt-4.1, gemini-pro, claude-3, qwen-Long, llama-3, deepseek-chat…).
- Gửi yêu cầu như thông thường (chat/completions, embeddings…), kèm tham số nhiệt độ, max_tokens… theo chuẩn OpenAI API.
- Tùy chọn cấu hình fallback/định tuyến để tự động chuyển sang mô hình khác khi lỗi hoặc vượt hạn mức.
- Kiểm thử độ trễ, tỷ lệ lỗi và tinh chỉnh alias để cân bằng giữa chất lượng, chi phí và tốc độ.
Trường hợp ứng dụng thực tế của AiHubMix
- Xây chatbot chăm sóc khách hàng: định tuyến sang mô hình rẻ hơn cho câu hỏi đơn giản, chuyển sang mô hình mạnh khi cần suy luận phức tạp. - Hệ thống RAG nội bộ: dùng embeddings từ nhà cung cấp tối ưu chi phí, nhưng sinh câu trả lời bằng mô hình mạnh để tăng độ chính xác. - Tạo nội dung đa ngôn ngữ: thử A/B giữa Claude, GPT, Gemini để chọn chất lượng văn phong tốt nhất. - Tóm tắt tài liệu/bảng ghi cuộc họp ở quy mô lớn: tận dụng đồng thời cao và cân bằng tải. - Công cụ hỗ trợ lập trình: so sánh khả năng sinh mã giữa nhiều mô hình để tối ưu trải nghiệm.
Ưu điểm và nhược điểm của AiHubMix
Ưu điểm:
- Chuẩn OpenAI API thống nhất, giảm công sức tích hợp đa nhà cung cấp.
- Hỗ trợ nhiều mô hình mới nhất, tránh khóa chặt với một bên.
- Định tuyến linh hoạt, có fallback giúp tăng độ ổn định.
- Hiệu năng tốt với khả năng đồng thời không giới hạn.
- Dễ thử nghiệm/A-B để tối ưu chất lượng – độ trễ – chi phí.
Nhược điểm:
- Phụ thuộc thêm một lớp proxy có thể tăng độ trễ trong một số kịch bản.
- Một số tính năng đặc thù từng nhà cung cấp có thể không ánh xạ 1-1 qua chuẩn chung.
- Giới hạn/biến động từ nhà cung cấp gốc vẫn có thể ảnh hưởng kết quả.
Các câu hỏi thường gặp về AiHubMix
Câu hỏi: AiHubMix khác gì so với gọi trực tiếp OpenAI hay Gemini?
Trả lời: Bạn dùng một chuẩn OpenAI API để truy cập nhiều mô hình, có định tuyến linh hoạt và fallback, giảm rủi ro phụ thuộc và rút ngắn thời gian tích hợp.
Câu hỏi: Có cần thay đổi mã nhiều khi chuyển sang AiHubMix?
Trả lời: Thường chỉ cần thay baseURL và khóa; cú pháp gọi theo chuẩn OpenAI API được giữ nguyên.
Câu hỏi: AiHubMix hỗ trợ những mô hình nào?
Trả lời: Các mô hình từ OpenAI, Google Gemini, DeepSeek, Llama, Qwen (Alibaba), Claude, Moonshot AI, Cohere và được cập nhật khi có phiên bản mới.
Câu hỏi: Có giới hạn đồng thời khi gửi yêu cầu?
Trả lời: AiHubMix hướng tới unlimited concurrency; tuy nhiên, hạn mức từ nhà cung cấp gốc vẫn có thể tác động trong một số tình huống.
Câu hỏi: Có hỗ trợ embeddings và chat/completions?
Trả lời: Có, AiHubMix tuân theo chuẩn OpenAI API nên có thể gọi các endpoint phổ biến như chat/completions và embeddings.
Câu hỏi: Tôi có thể thiết lập fallback giữa các mô hình?
Trả lời: Có, bạn có thể cấu hình định tuyến dự phòng để tự động chuyển sang mô hình khác khi gặp lỗi hoặc tắc nghẽn.