Confident AI
打開網站-
工具介紹:整合式LLM評測平台:14+指標、追蹤與資料集管理;支援人工回饋與自動化測試,DeepEval相容,並提供基準與護欄。
-
收錄時間:2025-11-06
-
社群媒體&信箱:

工具資訊
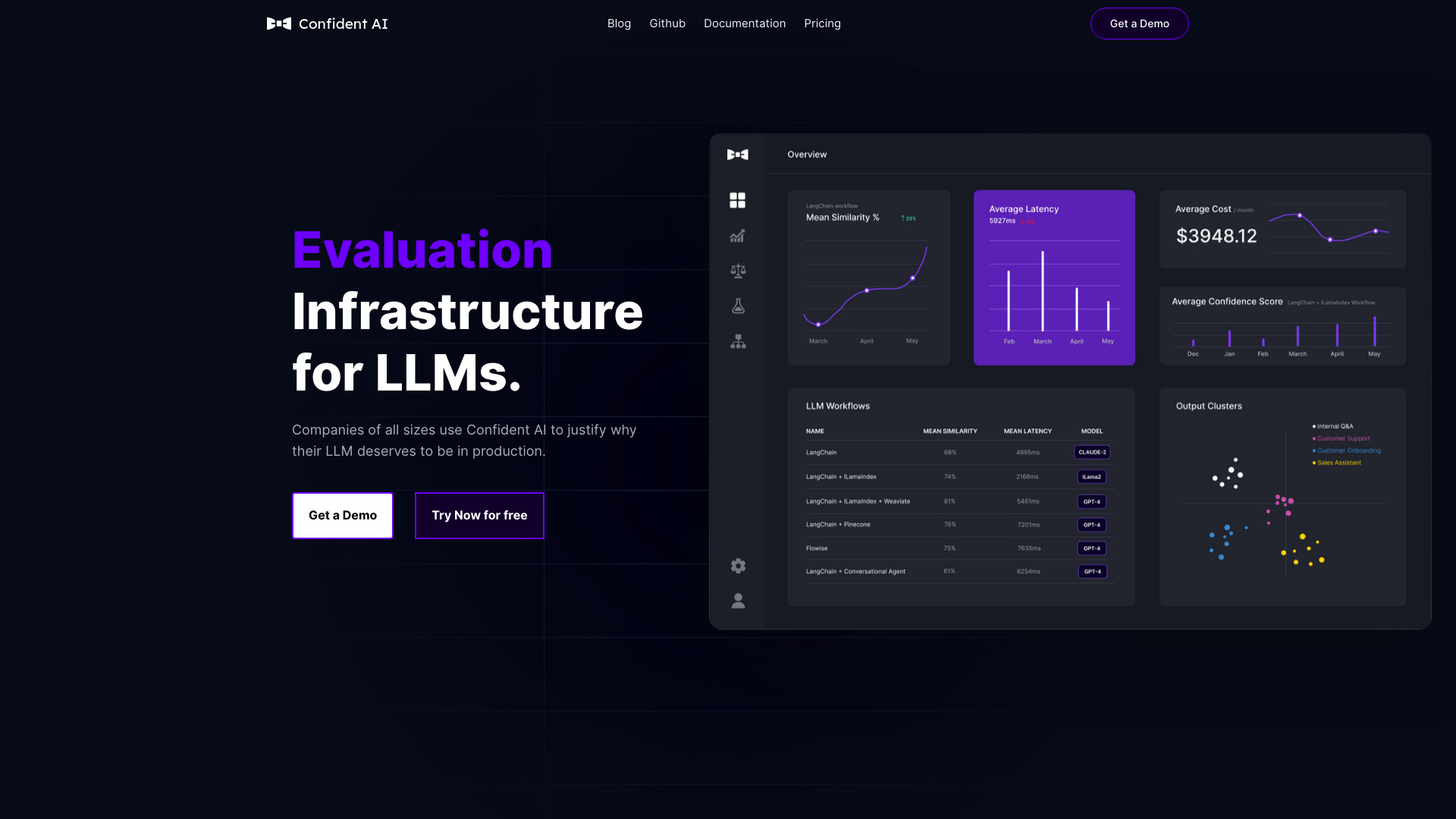
什麼是 Confident AI
Confident AI 是一個面向工程團隊的全方位大型語言模型(LLM)評測與實驗平台,強調以可重現、可追蹤的方式評估與改進各類生成式 AI 應用。它提供超過 14 種以上的客觀與主觀指標,協助團隊在單一介面中進行基準測試、實驗管理、資料集治理、效能監控與人類回饋整合,讓模型品質改善有據可依。透過與開源框架 DeepEval 的緊密搭配,使用者能快速建立評測基準,將指標與商業目標對齊,並以追蹤(tracing)機制理解每一次推理路徑與誤差來源。平台具備明確的資料集策展流程與實驗設計工具,支援提示、模型與超參數的系統化探索,並能自動化回歸測試,確保每次改版都能穩定提升,而非引入品質倒退。對於需要向利害關係人清楚說明改進幅度與投入產出比的團隊,Confident AI 以可視化報表與指標對照呈現結果,幫助節省推理成本、縮短迭代時間,並提升決策可信度。無論是聊天機器人、RAG 搜尋、內容生成或多步驟代理任務,皆能在同一平台上建立一致的評測流程與品質門檻,讓 AI 系統的可靠性從實驗到生產持續演進。
Confident AI 主要功能
- 多維度評測指標:提供包含正確性、事實性、幻覺率、相關性、一致性、遵從度、可讀性與安全性等多種指標,支援客觀分數與人類主觀評分的綜合衡量。
- 實驗與基準測試:支援 A/B 測試、回歸測試與提示/模型/超參數掃描,讓團隊以可重現方式比較不同方案的影響。
- 資料集管理與策展:建立、清洗、版本控制與切分資料集的完整流程,確保實驗樣本具代表性並能持續擴充。
- 追蹤與可觀測性(Tracing):詳細記錄每次推理的上下文、提示、檢索項與模型回應,方便問題定位與誤差分析。
- 人類回饋整合(HF):導入標註與審核工作流,將人類評分納入評測迭代,持續校正指標與品質門檻。
- 品質護欄與政策對齊:設定門檻與規則以攔截高風險輸出,協助建立更穩健的生成式 AI 安全機制。
- 成本與延遲監測:量測推理成本、延遲與吞吐,平衡品質與效能,支持成本優化決策。
- 自動化測試與 CI/CD:將評測套件接入開發流程,每次變更自動執行回歸測試並產出報表。
- 與 DeepEval 整合:結合開源評測框架的彈性與社群資源,快速上手並保有可擴充性。
- API/SDK 介接:以程式化方式串接現有服務與資料管線,便於大規模與持續性評測。
Confident AI 適用人群
Confident AI 特別適合需要可重現評測與嚴謹品質管理的工程與產品團隊,包括機器學習工程師、平台工程、資料科學家、品質保證人員、產品經理與技術領導者。典型情境包含:建立企業級聊天機器人、研發 RAG 問答與內部知識助理、打造內容生成與審核流程、優化多步驟代理、評估提示工程策略,以及在敏感領域(如金融、法務、醫療等)導入模型時的安全性與合規把關。對於需要向管理階層或客戶清楚說明改進成效、並在成本與品質間取得平衡的團隊,這套平台能提供透明、量化且容易解讀的證據。
Confident AI 使用步驟
- 連接專案與資料來源:匯入既有資料集或以收集器建立評測樣本,並完成資料版本化設定。
- 設定指標與門檻:挑選與業務目標對齊的指標,定義品質門檻與失敗條件。
- 設計實驗:規劃提示、模型與超參數組合,建立基準方案與對照組。
- 執行與追蹤:運行實驗並啟用 tracing,收集輸出、上下文與中間步驟以利後續分析。
- 整合人類回饋:導入標註與審核流程,將人類評分與評語納入模型改進循環。
- 自動化測試:把評測套件接入 CI/CD,在每次改動時自動跑回歸測試並產生報告。
- 監控與告警:在生產環境持續監測品質、成本與延遲,當偏移或退步時觸發告警。
- 迭代與匯報:根據結果優化提示與管線,輸出可視化報表向利害關係人說明改進幅度。
Confident AI 行業案例
在金融服務中,團隊以 Confident AI 建立 RAG 問答的事實性與安全性評測,針對不同檢索策略與提示做 A/B 測試,最終降低幻覺並減少不必要的 API 調用成本。在電商場景,產品搜尋與商品諮詢助理透過相關性與可讀性指標迭代提示模板,達成更高轉換與更低延遲。在企業 IT 與客服領域,內部知識助理使用回歸測試確保每次知識庫更新後仍維持穩定品質,同時以 tracing 追蹤錯誤樣本定位檢索問題。內容平台則將人類回饋併入審核流程,以毒性與合規指標建立品質護欄,縮短審核週期並提升一致性。這些做法共同體現了以指標驅動的實驗文化,讓生成式 AI 在生產環境更可控與可信。
Confident AI 收費模式
收費模式可能依功能模組、使用規模、支援層級與部署需求而有所不同;若需最新方案、授權與報價,建議以官方資訊為準,並依團隊的實驗頻率、資料集規模與合規要求評估最合適的配置。
Confident AI 優點與缺點
優點:
- 指標完整且可擴充,能同時衡量品質、安全與可讀性等面向。
- 與 DeepEval 整合,兼具開源彈性與平台級可視化與治理能力。
- Tracing 與可觀測性完善,便於誤差分析與問題定位。
- 支援資料集策展、版本控制與回歸測試,提升改版可控性。
- 自動化評測融入 CI/CD,縮短迭代時間並降低回滾風險。
- 以報表與基準說服利害關係人,促進以數據驅動的決策。
- 透過實驗與門檻設計,幫助優化推理成本與效能。
缺點:
- 初期需要投入資料集清理與指標定義,導入成本較高。
- 進階功能與自訂指標可能需要工程資源維護。
- 與既有系統、資料倉庫或安全流程整合,需額外規劃。
- 對於規模較小或需求單一的專案,功能深度可能超出必要。
Confident AI 熱門問題
問:支援哪些模型與框架整合?
答:可與主流 LLM 供應商與自建模型串接,並透過與 DeepEval 的結合與 API/SDK 介面導入既有工作流程。
問:是否適用於多種用例(如聊天、RAG、代理或內容生成)?
答:適用。平台以指標為核心,能對齊不同任務目標並自訂評測標準,支援跨用例的一致評測流程。
問:如何把人類回饋導入評測循環?
答:可建立標註與審核工作流,將人類評分與評論併入計分與報表,並作為後續實驗與品質門檻調整的依據。
問:能否幫助降低推理成本與延遲?
答:透過實驗比較與自動化測試,找出在品質不受損下更具成本效益與更快回應的組合,並以監測與門檻控制避免不必要的呼叫。
問:如何向利害關係人展示改進成效?
答:以可視化儀表板、前後版本對照與可重現基準呈現結果,清楚展示最佳化帶來的品質提升與成本變化。
問:能否與現有資料與工程管線整合?
答:可透過 API、事件追蹤與資料匯出融入現有數據與 CI/CD 管線,於開發與生產環境持續運行評測與監控。