Confident AI
打开网站-
工具介绍:一体化LLM评测平台,14+指标、追踪与数据集管理;支持人类反馈与自动化测试。DeepEval开源框架兼容,基准与护栏一站搞定。
-
收录时间:2025-11-06
-
社交媒体&邮箱:

工具信息
什么是 Confident AI
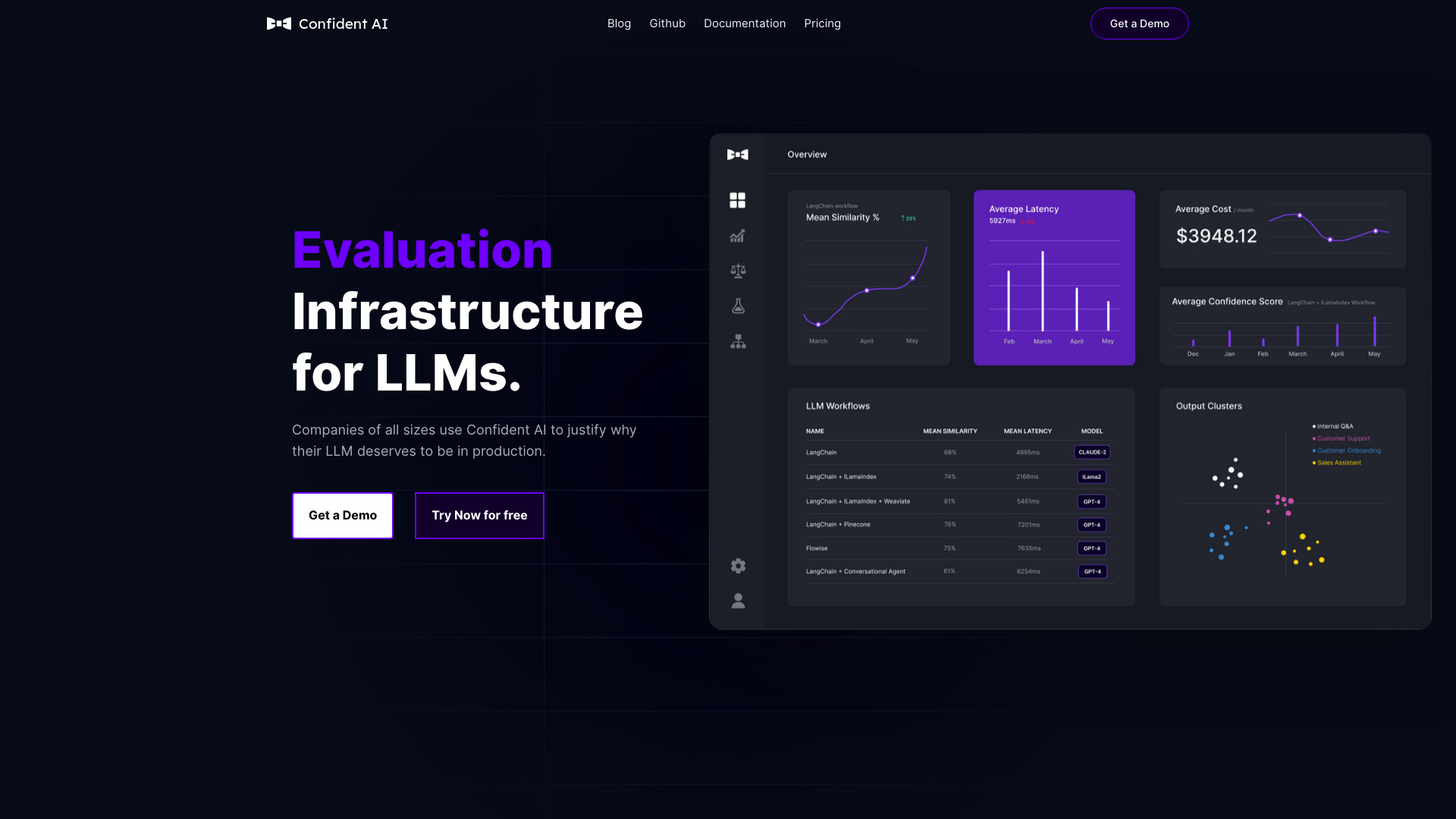
Confident AI 是一体化的大语言模型评测与改进平台,由开源评测工具 DeepEval 的创建团队打造,面向工程与产品团队提供覆盖全流程的 LLM 质量管理能力。平台内置十余类专业指标,可用于构建与运行评测实验、管理与标注数据集、在线监控模型表现,并将人类反馈融入评测闭环,持续提升应用的准确性、稳健性与可解释性。通过与开源框架协同,Confident AI 能快速对接各类模型与业务场景,统一指标口径与基线,配合调用链追踪记录上下文与输出,支持自动化回归测试、基准对比与安全护栏校验。在实践中,它帮助团队高效筛选提示词方案、优化推理开销、验证版本迭代效果,并以结构化证据向利益相关方呈现 AI 系统的改进幅度与可信度。
Confident AI主要功能
- 多维评测指标:覆盖准确性、相关性、事实一致性、鲁棒性、毒性与偏见、敏感信息泄露等十余类指标,支持单轮与多轮对话、检索增强生成等场景。
- 实验与基准测试:对比不同模型、提示词、系统参数与数据切分,生成可复现实验报告与基准基线,量化改动带来的收益。
- 数据集管理:集中管理评测样本、标签与元数据,支持样本分层抽样、难例挖掘与数据版本化,便于回归验证。
- 调用链追踪:记录请求、上下文、检索结果与模型输出,定位失败用例并溯源问题来源。
- 人类反馈融合:引入标注与主观评分,结合自动指标进行加权汇总,建立贴近业务目标的综合评分。
- 自动化回归测试:将评测集成到开发流水线,监测每次改动的质量与成本影响,防止性能回退。
- 在线监控与告警:持续跟踪关键指标波动与异常模式,支持阈值告警与版本对比。
- 成本与延迟分析:关联质量与推理成本、响应时延,辅助做出性价比最优的模型与参数选择。
- 可扩展指标:根据领域目标自定义打分逻辑或组合指标,适配垂直行业合规与安全要求。
- 与开源框架协同:与 DeepEval 框架配合,既保留开源灵活性,又获得企业级可观测与治理能力。
Confident AI适用人群
适合构建与运营 LLM 应用的工程团队、数据科学与算法团队、产品与质量保障团队,以及需要对生成质量、合规与成本进行可量化管理的企业。尤其适用于问答检索(RAG)、客服助理、搜索与推荐、内容生成与审核、代码与办公助理等需要持续验证与回归评测的场景。
Confident AI使用步骤
- 接入模型与数据源:配置所用模型与推理接口,连接检索或知识库(如用于 RAG)。
- 导入或构建数据集:整理代表性样本与期望输出,按场景与难度进行标注与分层。
- 选择与对齐指标:从准确性、事实性、安全性、相关性等维度挑选指标,并设定权重与阈值。
- 设计实验方案:制定提示词、参数与模型版本的对比计划,设置随机种子与数据切分。
- 运行评测并追踪:批量执行实验,自动记录调用链、上下文与输出,生成结构化结果。
- 分析报告与难例:查看评分分布、回归对比与成本延迟画像,定位失败模式与边界案例。
- 融入人类反馈:对关键样本进行主观评审,校准或优化综合评分与判定规则。
- 接入流水线与监控:将评测嵌入 CI/CD 与线上监控,持续迭代并防止性能回退。
Confident AI行业案例
在客服问答场景中,团队以历史工单构建评测集,使用相关性与事实一致性指标验证 RAG 检索质量,并通过追踪定位召回不足的文档;在内容生成与审核中,采用毒性与合规性指标建立安全护栏,减少不当输出;在金融与法务场景,结合人类评审与严格事实性指标,评估摘要与解读的可靠性;在代码助理与搜索推荐中,通过回归测试与成本分析,比较不同模型与提示词方案的性价比,指导上线版本选择。
Confident AI优点和缺点
优点:
- 指标体系完善,覆盖质量、安全与鲁棒性等关键维度。
- 实验、追踪与数据集管理一体化,便于复现与审计。
- 支持人类反馈融合,评分更贴合业务目标。
- 自动化回归与在线监控,降低版本回退风险。
- 与开源工具协同,兼顾灵活性与企业级治理。
- 以证据驱动的报告与基线,便于对齐利益相关方。
- 质量、成本与时延联合分析,辅助性价比优化。
缺点:
- 前期需要梳理数据与指标体系,投入一定配置与标注成本。
- 指标选择与权重设定对专业度有要求,存在学习曲线。
- 对实时高并发场景,追踪与评测可能带来一定开销。
- 涉及敏感或私有数据时,需要配合企业合规与安全策略。
Confident AI热门问题
-
是否支持不同模型与供应商的评测?
支持对接多种模型与推理接口,可在统一指标与基线下进行跨模型对比与回归测试。
-
如何与开源评测框架协同使用?
可在开源框架中编排测试逻辑与用例,在平台侧统一进行数据集管理、追踪与报告汇总,兼顾灵活与可观测。
-
适用于 RAG 检索增强生成的评测吗?
适用。可对检索相关性、证据覆盖率与最终回答的事实一致性分别打分,并结合追踪定位召回或融合问题。
-
能否引入人类反馈提升评分可信度?
可以。支持将人工标注与主观评分融入综合指标,用于校准阈值、优化权重并指导模型与提示词迭代。
-
如何在持续交付流程中使用?
将关键评测集与指标接入 CI/CD,提交合并前自动运行回归测试,并对质量、成本与延迟变化给出可视化报告与告警。
-
是否支持自定义指标与领域规则?
支持根据业务目标编写或组合指标,加入领域约束与合规模型检查,形成贴合场景的评测基线。