Middleware
打開網站-
工具介紹:Middleware AI 全棧可觀測:統一監控基礎設施、日誌、APM;AI 即時告警、數據可視化與安全合規。
-
收錄時間:2025-11-09
-
社群媒體&信箱:




工具資訊
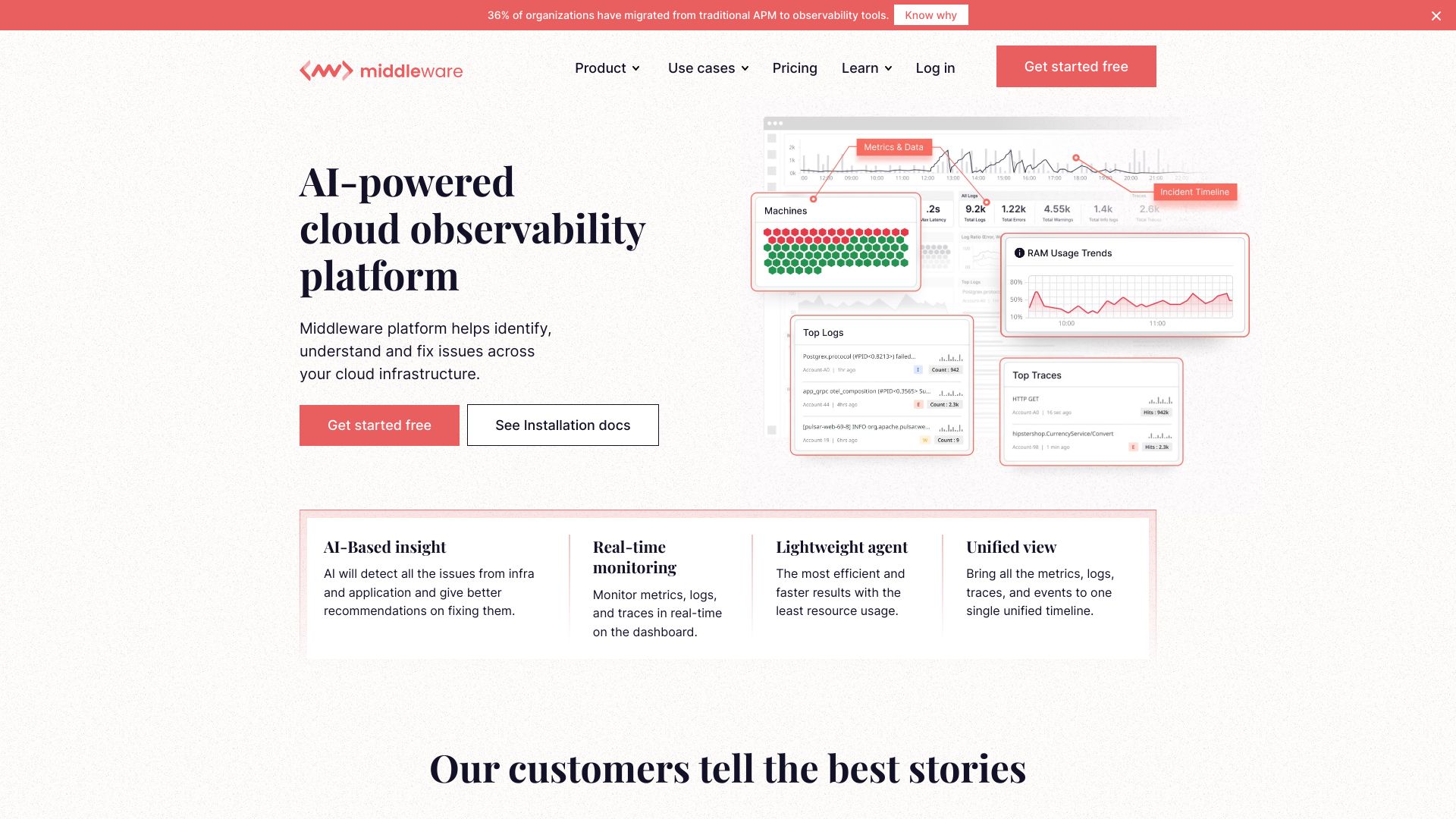
什麼是 Middleware AI
Middleware AI 是一套以可觀測性為核心的全端監控平台,聚合基礎設施監控、應用效能管理(APM)、日誌與事件流、分散式追蹤與即時告警於同一介面,協助團隊在複雜的雲端與微服務環境中維持高可用與高效能。它透過統一的資料管線收集指標(Metrics)、日誌(Logs)、追蹤(Traces)等遙測訊號,並以 AI 驅動的異常偵測與根因分析,縮短問題定位時間,降低平均修復時間(MTTR)。對於使用 Kubernetes、Serverless 或多雲架構的 DevOps 與 SRE 團隊而言,Middleware AI 能以儀表板與查詢語言快速呈現系統健康度、容量趨勢與服務相依性,同時提供細緻的告警路由與噪音抑制,避免通知疲勞。在資料治理方面,平台強調安全與權限控管,支援團隊協作、審計與合規流程;在效率方面,則以即時資料存取與彈性擴充應對尖峰流量與突發事件,讓工程團隊能專注於可靠性工程與持續優化,形成從觀測到行動的閉環。
Middleware AI 主要功能
- 基礎設施監控:整合雲資源、虛擬機、容器與 Kubernetes 叢集,提供節點健康度、資源用量與服務依賴視圖。
- APM 與分散式追蹤:追蹤請求路徑與延遲瓶頸,定位微服務間的效能問題與錯誤來源。
- 日誌集中化:支援多來源日誌收集、索引與全文檢索,結合追蹤與指標進行關聯分析。
- AI 異常偵測:以模型學習基線行為,自動識別異常尖峰、流量漂移與效能退化,降低誤報。
- 即時告警與路由:條件式告警、抑制與升級機制,依團隊、服務或嚴重度進行通知配置。
- 可客製儀表板:拖放式組件與查詢語言,建立 SRE/業務導向的視覺化看板與 SLO 追蹤。
- 根因分析與事後檢討:事件時間線、關聯指標與日誌快照,加速故障診斷與建立事後報告。
- 雲端與框架整合:相容常見公有雲、容器、資料庫與快取服務,支援 OpenTelemetry 等遙測標準。
- 存取與安全:細粒度 RBAC 權限、審計軌跡與資料遮罩,兼顧協作與合規需求。
- 成本與用量可視化:觀測資料與運行資源的用量趨勢,協助容量規劃與成本最佳化。
Middleware AI 適用人群
Middleware AI 適合在雲端或混合雲環境中運行關鍵服務的技術團隊,包括 DevOps、SRE、平台工程、後端與全端開發者,以及負責可靠性與合規的技術主管。對採用微服務、Kubernetes、事件驅動或多區域部署的團隊,平台能提供跨層面的可視化與關聯分析;對成長中的 SaaS、新創與企業級組織,則能在單一平台上覆蓋從基礎設施到應用的監控需求,降低工具分散帶來的維運負擔,並以資料驅動方式提升服務穩定度與使用者體驗。
Middleware AI 使用步驟
- 建立工作區:註冊並建立專案空間,設定組織與成員角色與權限。
- 連接雲端與環境:授權整合公有雲帳戶或匯入 Kubernetes 叢集,選擇需監控的資源。
- 部署代理與 SDK:安裝基礎設施代理、日誌收集器與 APM/追蹤 SDK,或啟用 OpenTelemetry 匯出。
- 設定資料來源:定義指標、日誌與追蹤的擷取規則、索引策略與保存期限。
- 建立儀表板與 SLO:使用範本或自訂查詢,配置關鍵服務的健康度看板與 SLO/SLA 門檻。
- 啟用告警策略:為延遲、錯誤率、資源用量等指標設置告警,定義路由、抑制與升級規則。
- 開啟 AI 偵測:啟用異常偵測與自動關聯分析,監測流量異常與性能退化。
- 日常運維與優化:在事件發生時透過時間線、關聯日誌與追蹤定位根因,並持續調整儀表板與門檻。
Middleware AI 行業案例
電商平台在大型促銷檔期透過 Middleware AI 監測訂單與支付服務的端到端延遲,於流量尖峰時即時觸發自動化擴容並將錯誤率維持在 SLO 內;金融科技團隊將核心 API 的分散式追蹤與稽核日誌關聯,快速定位第三方服務延遲造成的交易超時,並生成事後報告以符合合規要求;SaaS 供應商整合 Kubernetes 指標與應用日誌,發現某版本部署導致記憶體洩漏,透過回滾縮短 MTTR 並避免擴大影響;遊戲與串流服務則使用即時告警與 AI 偵測,提前發現區域性網路抖動,將中斷時間降到最低,改善玩家與觀眾體驗。
Middleware AI 優點與缺點
優點:
- 單一平台整合指標、日誌與追蹤,減少工具切換與資訊孤島。
- AI 驅動的異常偵測與關聯分析,加速根因定位並降低噪音。
- 深度支援雲端與 Kubernetes 堆疊,適配微服務與動態基礎設施。
- 彈性儀表板與查詢能力,能對應技術與業務雙重視角。
- 細緻的權限與審計設計,兼顧資料安全與團隊協作。
- 即時數據處理與告警,強化事件回應速度與可靠性工程。
缺點:
- 初期導入需整理遙測標準與資料管線,存在學習曲線。
- 高流量或長期保留設定可能增加存儲與索引成本。
- 若告警策略未調校,仍可能出現通知疲勞或誤報。
- AI 模型在罕見事件上可能需要額外標註與調優。
- 與既有監控堆疊的重疊度須評估,以避免工具冗餘。
- 跨多雲與多團隊情境下,治理與權限管理需明確規劃。
Middleware AI 熱門問題
-
問:是否支援 OpenTelemetry 與主流雲端服務整合?
答:支援以 OpenTelemetry 匯出指標、日誌與追蹤,並可整合常見的公有雲與容器平台,快速接入既有環境。
-
問:如何降低告警噪音與誤報?
答:可透過抑制規則、升級路由、時間視窗與 AI 基線,比對趨勢而非單點閾值,並以服務與嚴重度分層通知。
-
問:能否用於 SLO 與事後檢討(Postmortem)?
答:可設定 SLO 指標與誤差預算,並以事件時間線、關聯指標與日誌摘要生成事後報告,支援持續改進。
-
問:資料安全與權限如何管理?
答:提供細粒度 RBAC、審計軌跡與資料遮罩,能依團隊與環境分權,降低敏感資料外洩風險。
-
問:對 Kubernetes 與微服務效能診斷有何幫助?
答:透過工作負載與節點指標、分散式追蹤與服務拓撲,能快速定位瓶頸與資源爭用,支援版本回滾與容量規劃決策。