LiteLLM
ウェブサイトを開く-
ツール紹介:OpenAI互換のLLMゲートウェイ。100以上のモデル統合、コスト管理と監視、レート制限やガードレールも標準対応。
-
登録日:2025-10-21
-
ソーシャルメディアとメール:

ツール情報
LiteLLM AIとは
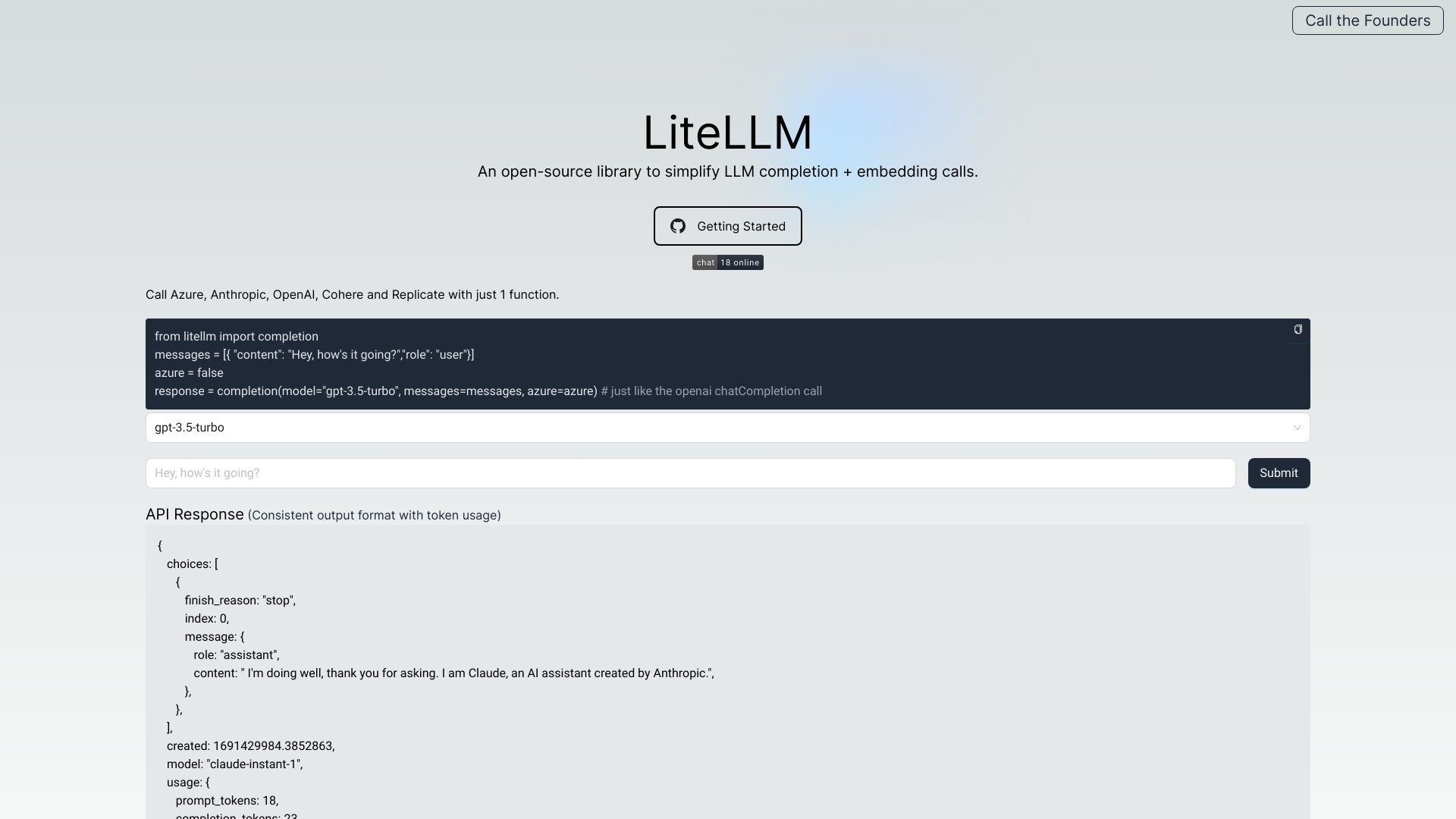
LiteLLM AIは、複数のLLMプロバイダを横断して統一的に扱えるOpenAI互換のLLMゲートウェイ(プロキシ)です。OpenAI、Azure OpenAI、Cohere、Anthropic、Replicate、Googleなど100以上のLLM/モデルを同一のAPI形式で呼び出せるため、アプリ側の実装をほぼ変更せずにモデルの切替・併用・フェイルオーバーが可能になります。認証情報やモデルアクセス権限の一元管理、負荷分散、コスト追跡と予算管理、ログ収集とエラートラッキング、レート制限やガードレールなど、運用の基盤機能を提供。OpenAI形式のレスポンス/例外を維持しつつ、観測性(オブザーバビリティ)とガバナンスを高め、LLM活用のスケールと信頼性を両立させます。さらに、バッチAPIによる大量推論の効率化、プロンプト管理とテンプレート化、S3への永続ロギング、パススルーエンドポイントによるベンダー固有機能の活用にも対応。利用状況の可視化や予算アラートにより、開発・運用・セキュリティ・FinOpsの各チームが共通の基盤上で連携し、マルチモデル戦略とコスト最適化を安全に推進できます。
LiteLLM AIの主な機能
- OpenAI互換API:リクエスト/レスポンス形式と例外仕様を統一し、最小限の変更で複数プロバイダを切替可能。
- 認証・アクセス管理:APIキーの一元管理、モデル単位のアクセス制御(RBAC)で安全に公開・共有。
- 負荷分散とフェイルオーバー:モデルやベンダー間でトラフィックを分散し、障害時は自動切替で可用性を確保。
- コスト追跡・予算管理:プロバイダ横断で使用量と費用を集計し、チーム/モデル別の予算やアラートを設定。
- ログ・エラートラッキング:全モデルの呼び出しログを一元化し、失敗率や遅延の傾向を可視化。S3ロギングにも対応。
- レート制限とガードレール:ユーザー/ルート/モデル別にスロットルを設定し、出力制御や安全策を適用。
- バッチAPI:大量リクエストを効率的に送信し、処理コストとレイテンシを最適化。
- プロンプト管理:テンプレート化・バージョン管理・差分検証で品質と再現性を担保。
- パススルーエンドポイント:必要に応じてベンダー固有機能をそのまま利用しつつ、ゲートウェイの統制も維持。
- LLM観測性:ダッシュボードでメトリクス、エラー、支出、成功率をモニタリング。
LiteLLM AIの対象ユーザー
マルチプロバイダを前提とするプロダクトチーム、プラットフォーム/MLエンジニア、SRE/オペレーション、セキュリティ/コンプライアンス、FinOps担当者に適しています。モデル比較・ABテスト、ベンダーロックイン回避、ガバナンス強化、コスト最適化、トラフィック制御やSLA準拠が求められる環境で特に有効です。
LiteLLM AIの使用手順
- 対象プロバイダ(OpenAI、Azure、Cohere、Anthropic、Google、Replicateなど)のAPIキーを準備し、LiteLLM AIに登録。
- ルーティングとモデルエイリアスを設定し、利用したいモデル群を論理名で管理。
- 必要に応じてレート制限、ガードレール、アクセス権限、予算アラートをポリシーとして定義。
- ログ保存先(例:S3)やエラートラッキング、メトリクス収集の設定を有効化。
- アプリ側のエンドポイントをOpenAI互換のLiteLLM AIゲートウェイに向け替え、既存のSDK/クライアントを継続利用。
- バッチAPIやパススルーエンドポイントを必要に応じて活用し、高スループットや固有機能を両立。
- ダッシュボードで成功率、レイテンシ、支出を監視し、ルーティングや予算を継続的に調整。
LiteLLM AIの業界での活用事例
カスタマーサポートでは、時間帯や負荷に応じて複数LLMに自動分散し、障害時は別モデルへフェイルオーバー。生成要約を扱うSaaSでは、ガードレールとレート制限で品質とSLAを担保しつつ、コストをリアルタイムに可視化。金融や医療の現場では、モデルアクセスの厳格な権限管理とS3ロギングによる監査証跡を整備。研究開発では、ABテストでモデル切替を高速化し、バッチAPIで大規模評価を効率化します。
LiteLLM AIの料金プラン
一般的な利用形態では、接続する各LLMプロバイダ(OpenAI等)のAPI利用料に準拠し、LiteLLM AIはその使用量と支出を横断的に追跡・集計します。導入形態(セルフホスト/マネージド)や追加機能の提供内容・価格は運用方針によって異なるため、最新情報は公式の案内をご確認ください。
LiteLLM AIのメリットとデメリット
メリット:
- OpenAI互換の統一インターフェースで実装負荷を最小化し、ベンダーロックインを回避。
- 負荷分散・フェイルオーバーにより可用性と信頼性を向上。
- コスト追跡と予算管理でFinOpsを強化し、無駄な支出を抑制。
- アクセス制御、レート制限、ガードレールでガバナンスと安全性を確保。
- ログと観測性により、品質改善とトラブルシューティングを迅速化。
デメリット:
- プロキシレイヤーの追加により、わずかなレイテンシ増加や運用の複雑性が生じる可能性。
- 各プロバイダ固有機能の完全な互換は難しく、挙動の差異に留意が必要。
- セルフホストの場合、可観測性やスケーリングの設計・保守コストが発生。
- ポリシー設定(権限・レート・予算)の設計が不十分だと、期待する統制効果が得られない可能性。
LiteLLM AIのよくある質問
-
質問1: OpenAI互換とは具体的に何が互換ですか?
リクエストボディやレスポンス形式、例外の扱いをOpenAI形式に揃えているため、既存のOpenAI向け実装を大きく変更せずに他プロバイダへ切替・併用できます。
-
質問2: 既存のOpenAI SDKをそのまま使えますか?
一般に、エンドポイントと認証先をLiteLLM AIのゲートウェイに向ける設定で流用可能です。詳細な設定は導入環境のポリシーに従ってください。
-
質問3: ログには機密データが残りますか?
ログ保存先や保有ポリシーは運用設計で調整できます。機密性要件に応じてマスキングや最小化を行い、不要なデータを送信しない方針を推奨します。
-
質問4: レイテンシへの影響はどの程度ありますか?
プロキシを経由するため小さなオーバーヘッドが発生し得ますが、実際の影響はネットワーク、モデル、設定(バッチ、キャッシュ等)に依存します。