Modal
打开网站-
工具介绍:面向AI与数据团队的无服务器平台,自带代码即可在GPU/CPU弹性运行,容器秒级启动,无需配置,支持推理与数据作业
-
收录时间:2025-10-21
-
社交媒体&邮箱:



工具信息
什么是 Modal AI
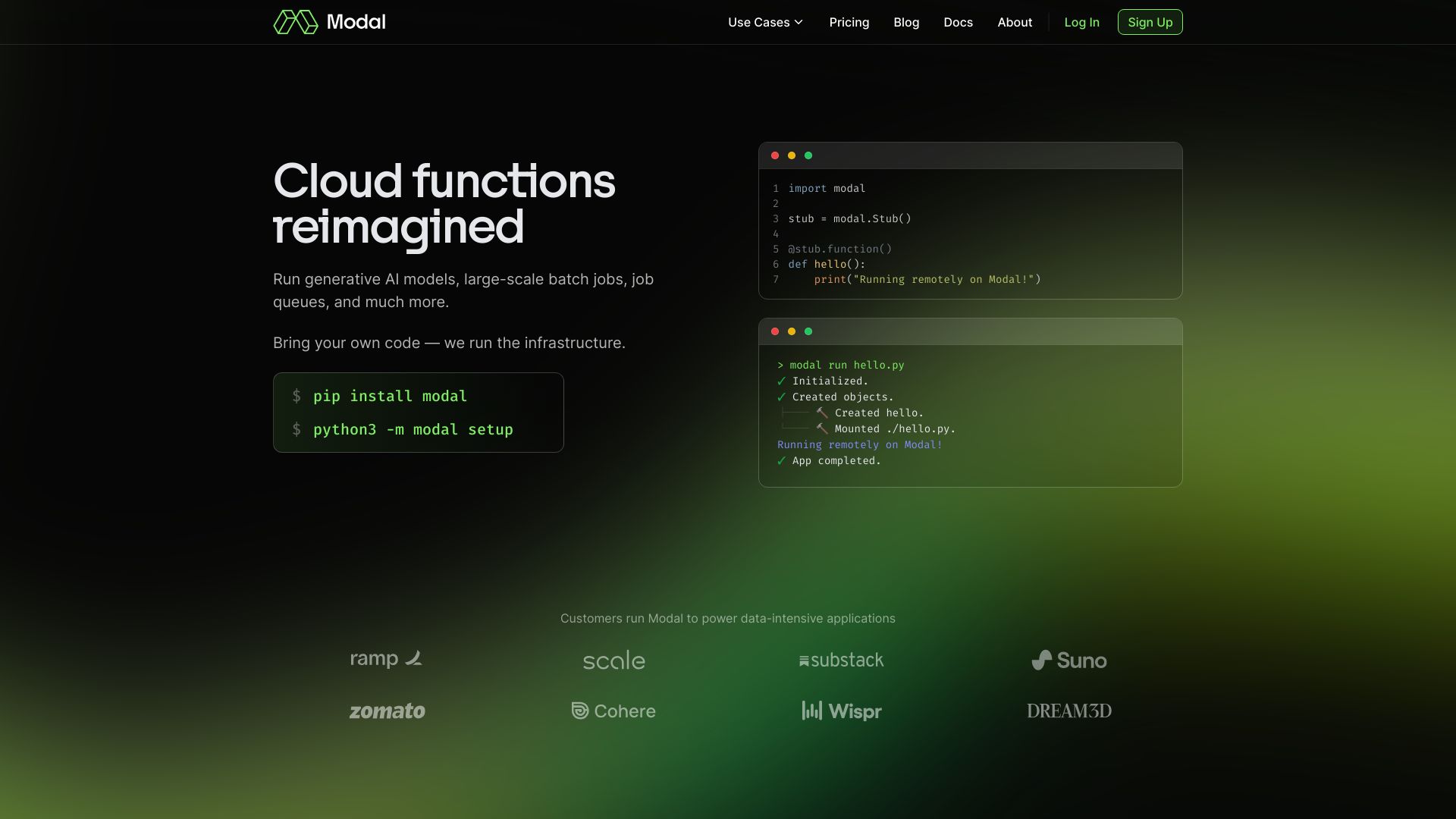
Modal AI 是面向 AI 与数据团队的无服务器计算平台,提供高性能 AI 基础设施,让用户把自己的代码直接带到云端,在统一的 CPU、GPU 集群上按需运行数据密集型与计算密集型工作负载。它以亚秒级容器启动、零配置文件、即时自动伸缩为核心,帮助团队快速上线机器学习推理、数据作业与工作流,而无需自建集群或维护繁杂的运维管线。通过在线推理端点、批处理任务与定时触发等形态,Modal AI 支持从原型到生产的一致环境与可重复部署,适配多种模型与数据处理场景。平台按请求自动扩容,空闲时缩至零,既保障性能又控制成本,并提供日志、指标与可观测能力,便于排障与性能优化,加速模型迭代与数据管道交付。开发者可使用熟悉的工具链封装依赖,快速构建轻量镜像;通过并发与队列控制吞吐;将模型暴露为 HTTP 接口供业务调用,或在计划任务中执行特征工程、ETL 与日志清洗。对于突发场景(如营销活动、A/B 实验),平台凭借快速冷启动与自动扩缩容,在高峰期平滑承载流量;管理侧提供凭证与权限、资源配额与成本视图,帮助企业在安全合规的前提下高效利用 GPU 算力。
Modal AI主要功能
- 无服务器 AI 基础设施:免运维管理与容量预估,请求驱动的自动扩缩容,空闲自动缩至零。
- 高性能计算资源:统一调度 CPU 与 GPU,支持模型推理、向量计算、数据预处理等密集型任务。
- 亚秒级容器启动:容器快速拉起,显著降低冷启动对在线推理尾延迟的影响。
- 自带代码与环境:直接携带现有代码与依赖上云,零配置文件即可运行,迁移成本低。
- 推理端点与批处理:一键将模型暴露为在线端点,或以批作业、工作流方式并行处理海量数据。
- 任务调度与触发:支持定时任务、事件驱动与队列触发,构建端到端数据管道。
- 观测与诊断:集中化日志、指标与追踪,辅助性能调优与成本治理。
- 安全与隔离:凭证管理、访问控制与环境隔离,降低数据与模型泄露风险。
- 成本优化:按量计费与自动扩缩容结合,减少空转与过度预留。
Modal AI适用人群
Modal AI 适合需要快速交付与弹性算力的团队与个人,包括:部署在线推理服务的 AI 工程师,运行特征工程与 ETL 的数据科学与数据平台团队,追求低运维成本的初创公司,进行实验与批处理计算的研究机构,以及需要临时 GPU 资源的后端与 MLOps 团队。在流量突发、迭代频繁或对成本敏感的业务场景中尤为适用。
Modal AI使用步骤
- 注册账户并创建项目,完成基础配额与权限设置。
- 准备代码与依赖,定义运行环境(例如基础镜像与依赖清单);也可直接携带现有代码,借助零配置文件快速启动。
- 为任务选择计算规格与并发策略,指定所需 CPU、GPU、内存与超时时间。
- 选择运行形态:部署为在线推理端点,或创建批处理作业、定时任务与事件触发器。
- 配置自动伸缩参数与队列策略,设置最大并发与阈值,保障延迟与吞吐。
- 部署并验证:进行功能与负载测试,连接上游/下游数据源或业务服务。
- 上线与运维:通过日志、指标与追踪监控性能与成本,基于观测结果滚动优化与版本化发布。
Modal AI行业案例
电商企业将推荐与搜索重排模型部署为在线推理端点,在大促高峰通过亚秒级容器启动与自动扩缩容承载突发流量,同时在低谷缩至零以控制成本。媒体与生成式内容平台把图像生成、视频转码与字幕对齐等 GPU 密集型作业以批处理并行执行,显著缩短周转时间。金融机构定时运行特征工程与评分卡批处理,在结算窗口按需扩容确保时效。数据平台团队把日志清洗、ETL/ELT 与特征管道迁移到无服务器环境,通过任务编排与重试机制提升稳定性与可维护性。
Modal AI收费模式
Modal AI 通常采用按量计费,费用与所消耗的计算与存储资源相关(例如 vCPU 时长、GPU 时长、存储与网络流量等),按需随用随付,空闲缩至零以减少成本。常见做法还包括提供一定的免费额度或试用以便开发验证,企业级场景可联系获取配额与定制报价。具体收费与优惠政策以官方公布为准。
Modal AI优点和缺点
优点:
- 无服务器与自动扩缩容,显著降低运维与容量规划成本。
- 亚秒级启动与弹性并发,适合突发流量的在线推理场景。
- 统一 CPU/GPU 平台,便于实验快速走向生产。
- 自带代码与零配置文件,迁移与上手门槛低。
- 按量计费与缩至零,成本可控且与业务负载匹配。
- 完善的日志与指标观测,便于性能调优与排障。
缺点:
- 对底层基础设施的可控性不如自建集群,存在一定供应商锁定。
- 复杂有状态或强依赖专有网络/存储的应用可能受限。
- 高峰期 GPU 资源可能出现排队或配额约束,需要提前规划。
- 尽管启动很快,冷启动仍可能影响极端尾延迟,需要通过并发预热与镜像瘦身优化。
- 合规与数据主权需求较高的行业需评估网络边界与访问控制方案。
Modal AI热门问题
-
问题 1: Modal AI 支持哪些语言与框架?
常见做法是以容器封装运行环境,主流编程语言与机器学习框架均可通过自定义镜像与依赖集成,在平台上运行推理与数据作业。
-
问题 2: 如何把现有模型部署为在线推理服务?
将代码与模型权重打包,定义入口与依赖,选择 CPU 或 GPU 规格后部署为端点;平台会提供自动扩缩容、负载并发与日志监控。
-
问题 3: 冷启动速度对延迟影响大吗?
平台支持亚秒级容器启动,通常能显著降低冷启动对尾延迟的影响;实际表现与镜像大小、依赖初始化与并发峰值有关。
-
问题 4: 能否运行批处理与定时任务?
可以。可将作业配置为批处理或以定时/事件触发运行,适合特征工程、ETL 与日志清洗等数据管道。
-
问题 5: 如何优化成本?
选择合适的 CPU/GPU 规格与并发上限,启用自动扩缩容与空闲缩至零,瘦身镜像、缓存依赖并监控热点任务,有助于降低计算与存储开销。
-
问题 6: 如何安全接入私有数据源?
通过凭证管理安全注入密钥,结合访问控制或专用网络入口访问内部服务;具体接入方式需根据企业网络策略与平台能力配置。