- Accueil
- Générateur dImages IA
- Modal
Modal
Site web ouvert-
Présentation de l'outil:Plateforme serverless IA: votre code sur GPU/CPU, autoscaling instantané
-
Date d'inclusion:2025-10-21
-
Réseaux sociaux et e-mails:



Informations sur l'outil
Qu’est-ce que Modal AI
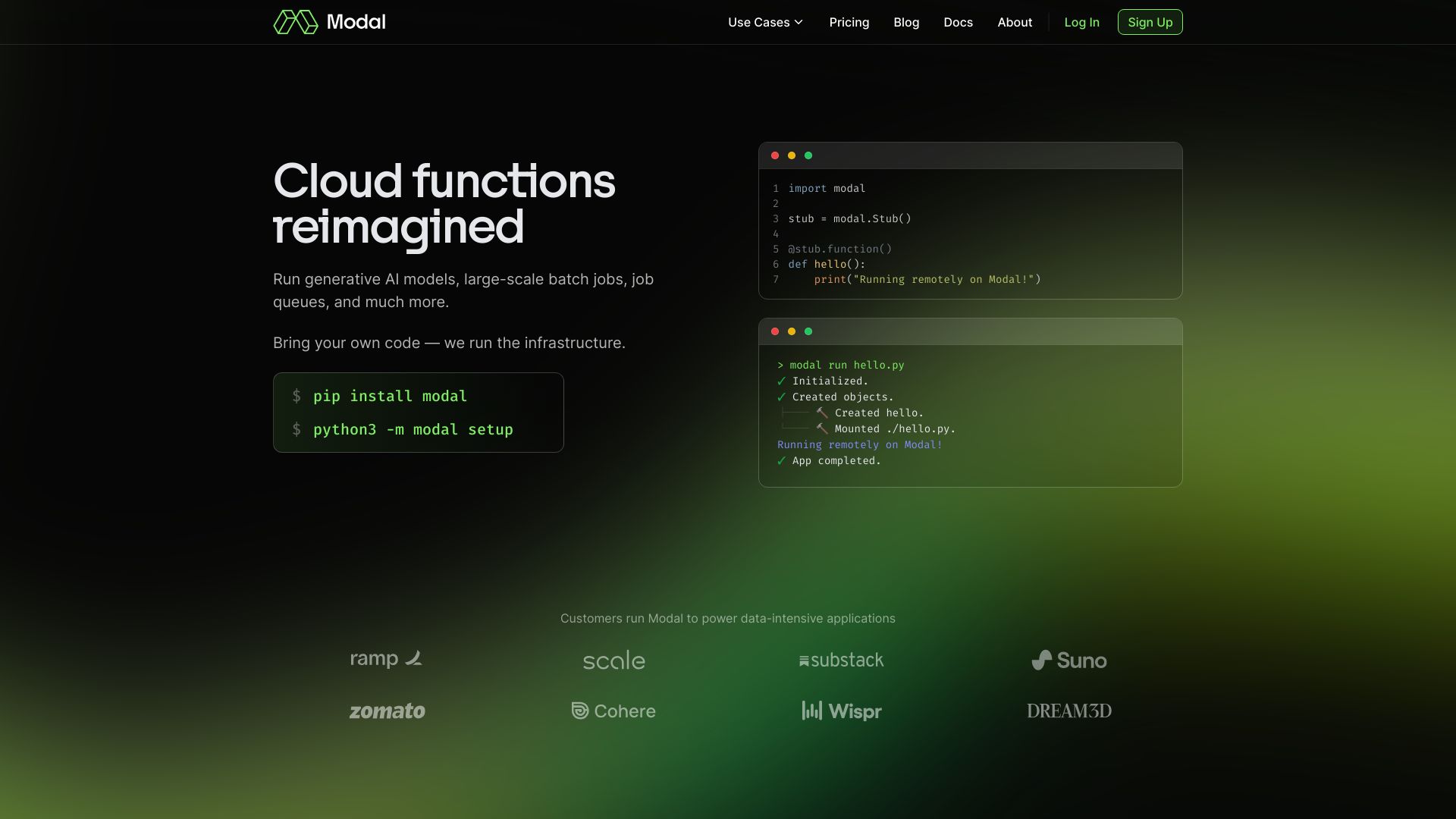
Modal AI est une plateforme d’exécution sans serveur conçue pour les équipes d’intelligence artificielle et de données. Elle fournit une infrastructure IA performante pour exécuter à grande échelle des charges de calcul intensives sur processeurs et accélérateurs graphiques. L’outil propose une mise à l’échelle automatique instantanée pour l’inférence en production et les travaux de données, avec des conteneurs qui démarrent en moins d’une seconde et un déploiement sans fichiers de configuration. Vous apportez votre code, la plateforme se charge du reste.
Fonctionnalités principales de Modal AI
- Exécution sans serveur haute performance pour charges de calcul intensives en IA et traitement de données.
- Mise à l’échelle automatique instantanée pour l’inférence en temps réel et les tâches par lots.
- Démarrage de conteneurs en moins d’une seconde, réduisant la latence au lancement.
- Apportez votre propre code et déployez sans fichiers de configuration, avec un flux simplifié.
- Ressources flexibles avec choix des profils de calcul sur processeurs et accélérateurs graphiques.
- Isolation par conteneurs pour des exécutions reproductibles et fiables.
- Réduction de l’opérationnel : pas de gestion d’infrastructure, de serveurs ni d’orchestrateurs.
À qui s’adresse Modal AI
Modal AI s’adresse aux équipes de science des données, ingénieurs en apprentissage automatique, développeurs de produits, ingénieurs données et organisations qui souhaitent déployer rapidement de l’inférence IA et des travaux de données à l’échelle, sans gérer d’infrastructure. Idéal pour les jeunes pousses comme pour les entreprises établies recherchant performance, élasticité et simplicité opérationnelle.
Comment utiliser Modal AI
- Préparez votre code et vos dépendances pour l’inférence ou les traitements de données.
- Définissez l’environnement d’exécution et les ressources nécessaires (processeurs, accélérateurs graphiques, mémoire).
- Emballez l’application dans un conteneur ou suivez le flux de déploiement proposé sans fichiers de configuration.
- Déployez une fonction, une API d’inférence ou un job de données selon votre cas d’usage.
- Activez la mise à l’échelle automatique en fonction de la charge et des objectifs de latence.
- Surveillez l’exécution, optimisez les ressources et itérez sur le code si nécessaire.
Cas d’utilisation de Modal AI
Déploiement d’API d’inférence IA à faible latence (vision, langage, recommandation), exécution de traitements par lots sur de grands volumes (préparation de données, agrégation, enrichissement), scoring de modèles en production, automatisation de pipelines de données récurrents, et calcul intensif pour analyses ponctuelles ou services en ligne sensibles à la charge.
Avantages et inconvénients de Modal AI
Avantages :
- Mise à l’échelle instantanée pour l’inférence et les travaux de données.
- Démarrage de conteneurs ultra-rapide, réduisant la latence de démarrage.
- Déploiement sans fichiers de configuration, apport de son propre code.
- Souplesse des ressources de calcul et haute performance.
- Pas de gestion d’infrastructure, focalisation sur le produit et les modèles.
Inconvénients :
- Dépendance à une plateforme tierce pour l’exécution et l’orchestration.
- Moins adapté si un contrôle matériel très fin ou des configurations réseau spécifiques sont requis.
- Les charges très intensives en accélérateurs graphiques peuvent nécessiter une optimisation attentive des coûts.
Questions fréquentes sur Modal AI
-
Modal AI prend-il en charge des charges sur processeurs et accélérateurs graphiques ?
Oui, la plateforme permet d’exécuter des calculs intensifs sur des ressources de calcul générales et graphiques, selon les besoins de la charge.
-
Puis-je déployer de l’inférence en temps réel et des traitements par lots ?
Oui, Modal AI s’adresse à la fois à l’inférence en production à faible latence et aux travaux de données planifiés ou récurrents.
-
Dois-je gérer des serveurs ou des fichiers de configuration complexes ?
Non, le déploiement est sans serveur et ne requiert pas de fichiers de configuration, ce qui simplifie la mise en production.
-
Comment la mise à l’échelle est-elle gérée ?
La plateforme ajuste automatiquement les ressources en fonction de la charge et du trafic, afin de maintenir performance et disponibilité.