Modal
Abrir sitio web-
Introducción de la herramienta:Infra serverless para IA: tu código en GPU/CPU con autoscaling al instante
-
Fecha de inclusión:2025-10-21
-
Redes sociales y correo electrónico:



Información de la herramienta
¿Qué es Modal AI?
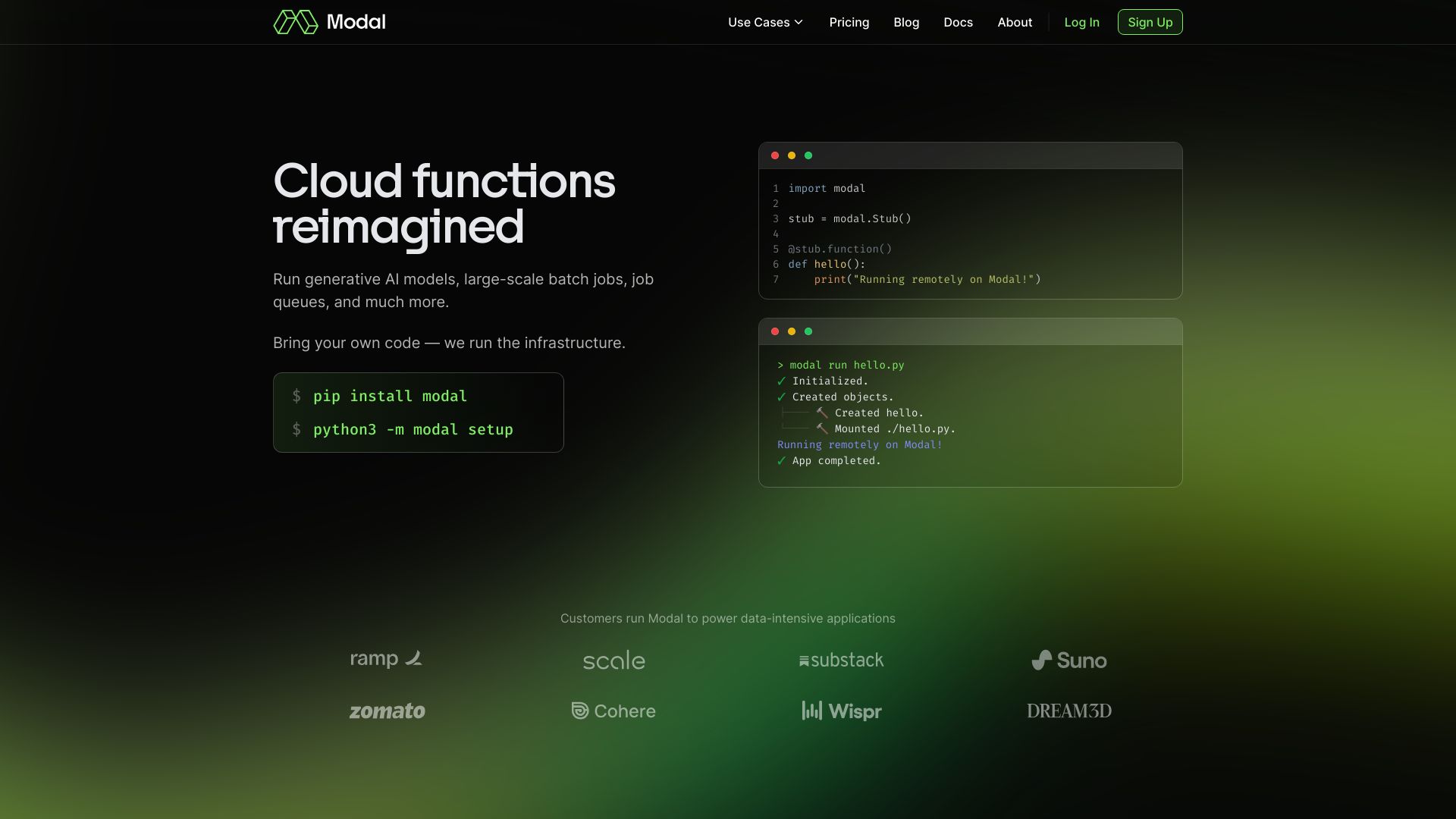
Modal AI es una plataforma serverless diseñada para equipos de IA y datos que necesitan ejecutar cómputo intensivo con alto rendimiento sin gestionar servidores. Permite llevar tu propio código y correr cargas en CPU y GPU a escala, desde inferencia de modelos de ML hasta trabajos de datos batch. Su infraestructura optimiza el arranque de contenedores en subsegundos y ofrece autoscaling instantáneo para responder a picos de demanda. Con cero archivos de configuración, agiliza el paso de prototipo a producción y reduce la complejidad operativa.
Principales características de Modal AI
- Plataforma serverless de alto rendimiento: ejecuta cargas de IA y datos sin aprovisionar ni mantener servidores.
- Bring your own code: utiliza tu propio código y librerías sin refactorizaciones complejas.
- Soporte CPU y GPU a escala: elige recursos de cómputo según la carga, desde tareas ligeras hasta procesamiento intensivo.
- Autoscaling instantáneo: escala inferencias de ML y trabajos de datos automáticamente ante variaciones de demanda.
- Arranque de contenedores en subsegundos: minimiza la latencia y acelera el tiempo a la primera respuesta.
- Cero archivos de configuración: despliegue simplificado, menos fricción y menores errores operativos.
- Ejecución basada en contenedores: entornos reproducibles y consistentes de desarrollo a producción.
¿Para quién es Modal AI?
Modal AI es ideal para equipos de ingeniería de ML, científicos de datos y data engineers que requieren escalar inferencias y data jobs sin gestionar infraestructura. También beneficia a startups que buscan llegar rápido a producción, a empresas con picos de tráfico impredecibles y a investigadores que necesitan GPU bajo demanda para ejecutar cómputo intensivo con eficiencia.
Cómo usar Modal AI
- Regístrate e inicia un proyecto para tu aplicación de IA o procesamiento de datos.
- Prepara tu entorno: empaqueta la app en un contenedor o define las dependencias necesarias.
- Sube tu código y selecciona los recursos de cómputo apropiados (CPU, GPU y memoria).
- Configura el tipo de carga: inferencia de ML, trabajos de datos o tareas batch.
- Despliega y ejecuta; la plataforma aplica autoscaling para adaptarse a la demanda.
- Supervisa la ejecución y optimiza parámetros según el rendimiento y la utilización.
Casos de uso de Modal AI en la industria
En comercio electrónico, servir modelos de recomendación o ranking con baja latencia gracias a arranques en subsegundos. En fintech, ejecutar inferencias antifraude y scoring bajo picos variables de tráfico. En analítica y BI, orquestar trabajos de datos y pipelines de preparación de características a escala. En I+D, correr experimentos que requieren GPU sin gestionar clústeres, acelerando ciclos de iteración y pruebas.
Ventajas y desventajas de Modal AI
Ventajas:
- Escalado instantáneo para inferencia de ML y trabajos de datos.
- Arranque en subsegundos que reduce la latencia inicial.
- Cero archivos de configuración, menor complejidad operativa.
- Flexibilidad de cómputo en CPU y GPU con entornos basados en contenedores.
- Bring your own code, sin restricciones fuertes sobre el stack.
Desventajas:
- Dependencia de un proveedor serverless para el tiempo de ejecución.
- Posible latencia inicial según la carga, aunque se optimice con arranque rápido.
- Menor control de bajo nivel frente a infra autogestionada en ciertos escenarios.
Preguntas frecuentes sobre Modal AI
-
¿Modal AI es una plataforma serverless?
Sí. Está orientada a ejecutar cargas de IA y datos sin que tengas que aprovisionar ni administrar servidores.
-
¿Puedo usar mi propio código y contenedores?
Sí. Modal AI permite bring your own code y ejecutar cargas en contenedores de forma reproducible.
-
¿Admite ejecución en GPU además de CPU?
Sí. Puedes seleccionar recursos de CPU o GPU según las necesidades de tus cargas.
-
¿Cómo maneja el escalado de la demanda?
Ofrece autoscaling instantáneo y arranque de contenedores en subsegundos para adaptarse rápidamente a picos de tráfico.
-
¿Necesito archivos de configuración para desplegar?
No. La plataforma está diseñada para operar con cero archivos de configuración, simplificando el despliegue.
-
¿Sirve para entrenamiento de modelos además de la inferencia?
Está enfocada en inferencia de ML y trabajos de datos; no obstante, permite ejecutar cargas intensivas en CPU/GPU cuando el flujo lo requiera.