firecrawl
ウェブサイトを開く-
ツール紹介:サイトをLLM向けデータ化。OSS、JSON/MD、動的対応クロール。回転プロキシや賢い待機も、ワークフロー統合も簡単。
-
登録日:2025-10-21
-
ソーシャルメディアとメール:


ツール情報
firecrawl AIとは?
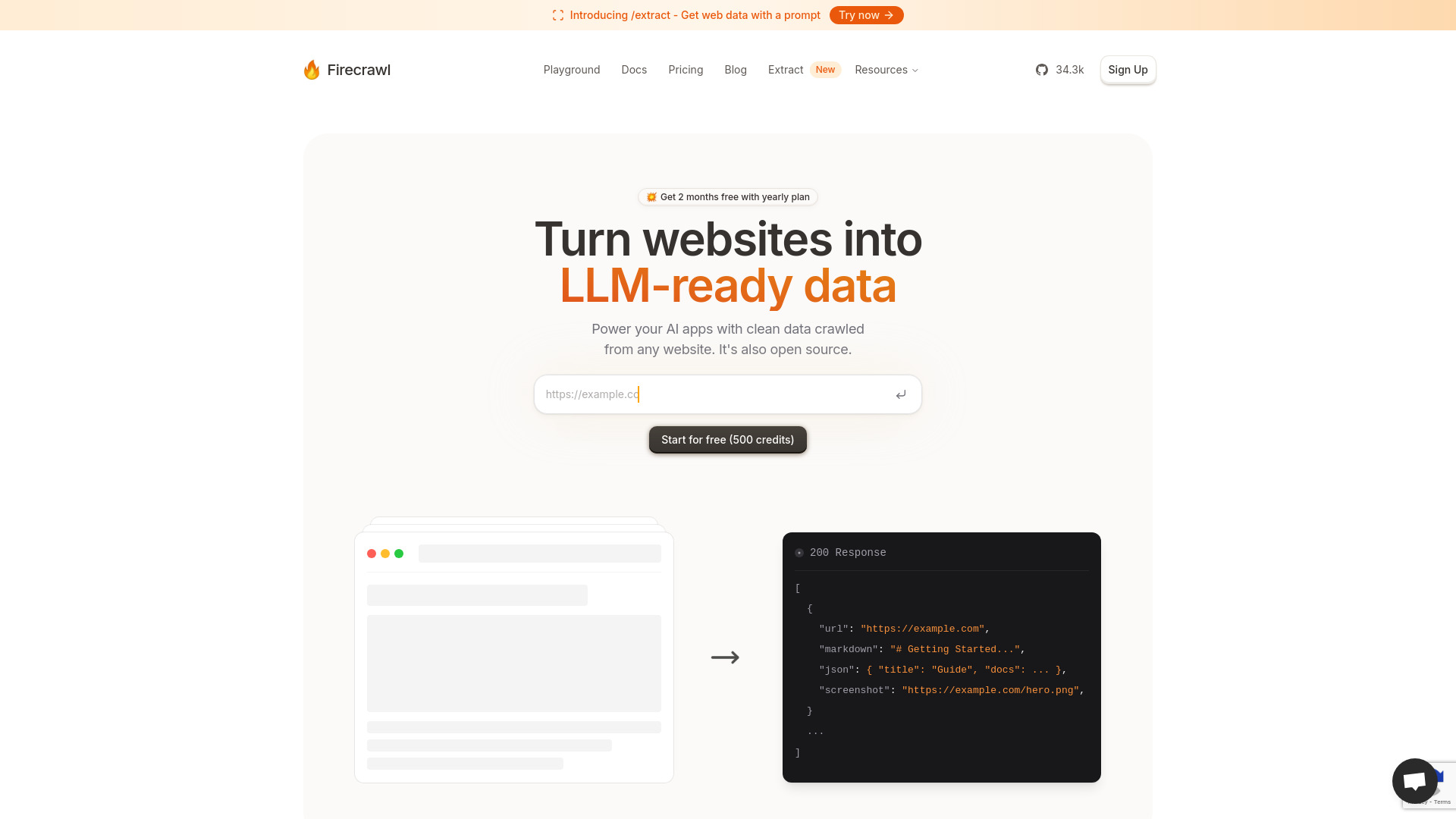
firecrawl AIは、任意のウェブサイトをLLM(大規模言語モデル)で扱いやすいクリーンなデータに変換するためのスクレイピング/クローリング基盤です。ページを横断的に巡回し、本文やメタ情報を抽出して、MarkdownやJSON、さらにスクリーンショットといった形式でエクスポートできます。オープンソースとして公開されており、拡張や自前運用がしやすいのが特徴です。加えて、回転プロキシ、オーケストレーション、レート制限のハンドリング、動的コンテンツのスマート待機(JavaScriptで描画される要素の読み込み待ち)など、実運用に必要な機能が揃っています。既存のAPIやワークフローへ統合しやすく、RAG用ナレッジベースの構築、検索インデクシング、コンテンツ分析などのデータパイプラインにおいて、ウェブ由来の非構造データを構造化・正規化する工程を効率化します。
firecrawl AIの主な機能
- ウェブサイトのスクレイピング/クローリングにより、複数ページを自動巡回して一括抽出
- Markdown・JSON・スクリーンショットなどマルチフォーマットでの出力に対応
- 動的コンテンツのスマート待機により、JavaScriptレンダリング後の要素も安定して取得
- 回転プロキシとレート制限ハンドリングで、ブロックや失敗率を抑えた堅牢な収集を実現
- オーケストレーション機能により、ジョブ管理・並列実行・再試行などの運用を効率化
- 重複排除や抽出結果の正規化により、LLM向けのクリーンデータを生成
- API経由で既存のETL・ワークフローへ容易に統合、RAGや検索の前処理に最適
- オープンソースベースで拡張可能、自前ホスティングにも適した柔軟な構成
firecrawl AIの対象ユーザー
LLMアプリケーション開発者、機械学習・データエンジニア、コンテンツ運用チーム、SEO/リサーチ担当、プロダクトマネージャーなど、ウェブからのデータ抽出を安定稼働させたいユーザーに適しています。特に、RAG向けのナレッジベース構築、競合・価格調査、ニュース監視、技術ドキュメントの収集、サポートFAQの自動生成など、継続的なクローリングと構造化が求められるシーンで有効です。
firecrawl AIの使い方
- 利用形態を選択:オープンソース版の自前ホスティングまたはクラウド/APIを選ぶ。
- シードURLを設定:クロール開始点となるURLやドメイン、対象セクションを指定する。
- スコープと制御を設定:クロール深度、並列数、レート制限、待機条件(動的レンダリング待ち時間など)を調整。
- 出力形式を選択:Markdown、JSON、スクリーンショットなど用途に合わせて設定。
- ジョブを実行:オーケストレーションでキューイングし、失敗時の再試行や回転プロキシを有効化。
- 結果を取得:APIまたはストレージから抽出結果を取得し、正規化・フィルタリングを行う。
- 下流へ連携:ベクターデータベースや検索インデックス、ダッシュボード、LLMパイプラインに投入。
- 運用最適化:スケジュール実行、差分更新、ログ監視で精度とコストをチューニング。
firecrawl AIの業界での活用事例
メディア・出版では記事アーカイブをクローリングし、Markdown/JSONへ変換してRAGのナレッジベースを構築。Eコマースでは商品ページを定期巡回し、価格・属性情報を抽出して競合分析や価格最適化に活用。SaaS/スタートアップではヘルプセンターやドキュメントサイトを取り込み、チャットボットや検索の精度向上に役立てます。リサーチ部門では規制・学術サイトをクロールし、要点抽出と要約の前処理に利用。いずれも、動的コンテンツ対応やレート制限対策、オーケストレーションにより、安定した大規模収集が可能です。
firecrawl AIの料金プラン
firecrawl AIはオープンソースとして利用でき、自前ホスティングではインフラ費用を中心に運用できます。クラウド/マネージド版のAPIも用意されており、一般的に使用量や処理ボリュームに応じた課金モデルで運用されます。要件(クロール規模、出力形式、並列数など)に合わせて、コストと運用負荷のバランスを取る選択が可能です。
firecrawl AIのメリットとデメリット
メリット:
- LLM/RAG向けに最適化されたクリーンで再利用しやすいデータを生成
- Markdown・JSON・スクリーンショットのマルチフォーマット出力に対応
- 回転プロキシとレート制限ハンドリングで大規模クロールを安定運用
- 動的コンテンツへのスマート待機でSPA等からの抽出精度を向上
- オープンソース基盤で拡張・自前運用がしやすく、API連携も容易
- オーケストレーションにより再試行・並列化・スケジューリングを一元管理
デメリット:
- 対象サイトの構造や対ボット対策により、抽出精度や到達性が左右される
- 動的レンダリングやスクリーンショットはリソース消費が増え、コストに影響
- 大規模クロールではプロキシ管理やレート制御など運用設計が必要
- 法的・倫理面の配慮(利用規約やアクセス制御の遵守)が不可欠
firecrawl AIに関するよくある質問
-
質問: 動的コンテンツのページからもデータを取得できますか?
はい。スマート待機により、JavaScriptで描画される要素のロードを考慮して抽出できます。
-
質問: どのような出力形式に対応していますか?
主にMarkdownやJSON、さらにページのスクリーンショットを生成できます。用途に応じて使い分け可能です。
-
質問: スクレイピングとクローリングの違いは何ですか?
スクレイピングは指定ページからの情報抽出、クローリングはリンクを辿ってサイト全体を巡回する処理を指します。firecrawl AIは両方をサポートします。
-
質問: RAGや検索システムへの統合は簡単ですか?
API経由で抽出結果を取得し、正規化したうえでベクターデータベースや検索インデックスに投入できます。
-
質問: ブロックを避けるための機能はありますか?
回転プロキシやレート制限のハンドリング、再試行などで失敗率を抑える設計が可能です。
-
質問: 自前ホスティングとクラウド版の違いは?
自前ホスティングは柔軟性が高くコスト最適化に向き、クラウド版は運用管理を委ねて迅速にスケールできます。
-
質問: 運用時の注意点はありますか?
対象サイトの利用規約やアクセスルールを確認し、レート制御・ログ監視・差分更新などの設計で安定稼働を目指してください。