firecrawl
Mở trang web-
Giới thiệu công cụ:Biến web thành dữ liệu LLM. Mã nguồn mở, JSON/MD, chờ thông minh.
-
Ngày thêm:2025-10-21
-
Mạng xã hội & Email:


Thông tin công cụ
firecrawl AI là gì
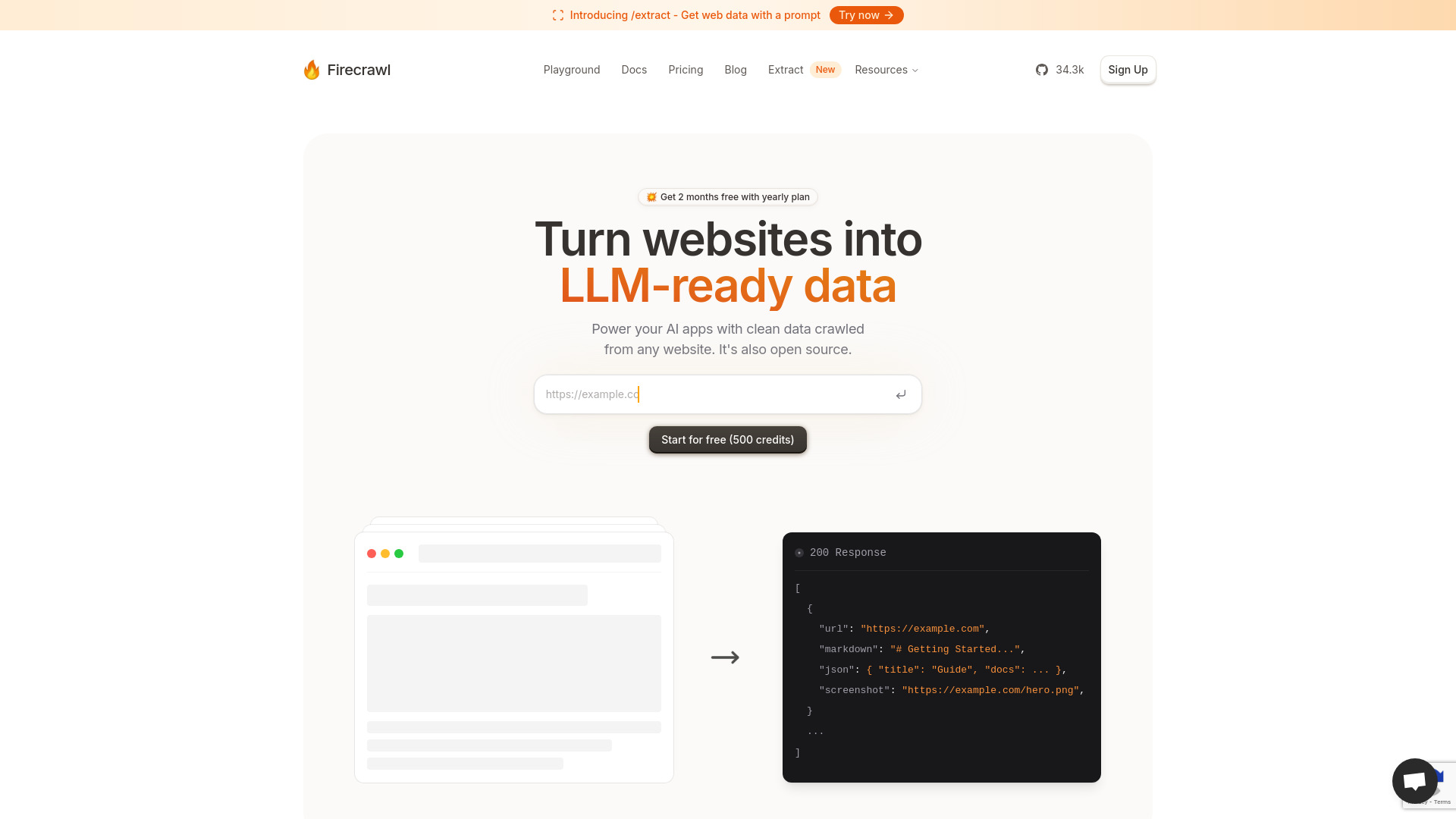
firecrawl AI là một công cụ mã nguồn mở giúp biến bất kỳ website nào thành dữ liệu “LLM‑ready” sạch và có cấu trúc. Công cụ hỗ trợ crawl và scrape toàn trang hoặc theo chiều sâu, trích xuất nội dung dưới dạng Markdown, JSON và ảnh chụp màn hình để dùng ngay trong các ứng dụng AI như RAG, tác tử (agent) hay pipeline ETL. Với xoay proxy, orchestration, xử lý rate limit và chờ thông minh cho nội dung động, firecrawl AI tối ưu độ ổn định khi thu thập dữ liệu. Công cụ tích hợp linh hoạt vào quy trình hiện có (API, workflow, nền tảng MLOps), giúp đội ngũ kỹ thuật tăng tốc đưa dữ liệu web chuẩn hóa vào mô hình mà không phải viết nhiều mã tùy biến.
Tính năng chính của firecrawl AI
- Thu thập dữ liệu web theo chiều sâu: hỗ trợ crawl đa tầng từ URL hạt giống, tôn trọng robots.txt và giới hạn miền.
- Trích xuất đa định dạng: xuất Markdown sạch, JSON có cấu trúc và screenshots để phục vụ cả NLP lẫn kiểm chứng trực quan.
- Xử lý nội dung động: chờ tải JavaScript thông minh, giảm thiếu hụt nội dung với các trang SPA/CSR.
- Xoay proxy và giới hạn tốc độ: hạn chế lỗi tạm thời, phân phối tải, xử lý rate limit ổn định.
- Orchestration và retry: điều phối luồng crawl, tự động thử lại khi gặp lỗi mạng hoặc phản hồi bất thường.
- Làm sạch và chuẩn hóa nội dung: loại bỏ phần thừa (menu, quảng cáo), giữ cấu trúc tiêu đề/đoạn để phù hợp chunking cho RAG.
- Tích hợp dễ dàng: API/SDK và kết nối với workflow, pipeline dữ liệu, kho lưu trữ hoặc công cụ tìm kiếm.
- Tùy biến phạm vi: lọc đường dẫn, chọn độ sâu, đặt quota, lịch chạy theo nhu cầu.
- Khả năng mở rộng: vận hành song song trên nhiều tác vụ để tăng tốc thu thập.
firecrawl AI phù hợp với ai
Phù hợp với nhóm xây dựng ứng dụng AI (RAG, chat trên tài liệu, agent), đội dữ liệu/ML cần pipeline ETL từ web, nhà nghiên cứu thị trường/cạnh tranh, SEO kỹ thuật thu thập nội dung quy mô lớn, nhà báo dữ liệu, và doanh nghiệp muốn đồng bộ tri thức công khai từ website đối tác/đối thủ vào hệ thống nội bộ.
Cách sử dụng firecrawl AI
- Cài đặt và cấu hình: thiết lập qua API/SDK hoặc môi trường tự lưu trữ; khai báo khóa API (nếu dùng dịch vụ) và tham số mặc định.
- Chọn nguồn dữ liệu: nhập một hoặc nhiều URL hạt giống, kèm ràng buộc miền, mẫu đường dẫn, hoặc tải sitemap để định hướng crawl.
- Đặt chiến lược crawl: chọn độ sâu, giới hạn trang, lịch chạy, quy tắc loại trừ, và cấu hình xử lý nội dung động.
- Chọn định dạng đầu ra: bật/tắt xuất Markdown, JSON, screenshots; xác định cấu trúc trường cần trích xuất.
- Tối ưu độ ổn định: bật xoay proxy, thiết lập rate limit, timeout, retry và quy tắc backoff khi gặp lỗi.
- Chạy và giám sát: khởi động tác vụ, theo dõi log, số trang thu thập, tỷ lệ lỗi và thời gian xử lý.
- Đưa vào pipeline: lưu kết quả vào kho dữ liệu, chỉ mục tìm kiếm hoặc công cụ vector hóa để phục vụ LLM/RAG.
- Bảo trì định kỳ: thiết lập crawl lặp để cập nhật nội dung và phát hiện thay đổi.
Trường hợp ứng dụng trong ngành với firecrawl AI
Trong thương mại điện tử, đội nội dung dùng firecrawl AI thu thập mô tả sản phẩm, thuộc tính và hình ảnh để làm giàu catalog và xây dựng trợ lý tìm kiếm ngữ nghĩa. Với tài chính, nhóm phân tích crawl báo cáo, trang quan hệ nhà đầu tư và tin tức để cập nhật cơ sở tri thức cho mô hình hỏi đáp. Ở lĩnh vực SaaS, đội hỗ trợ khách hàng chuyển tài liệu hướng dẫn trực tuyến thành dữ liệu Markdown sạch để huấn luyện chatbot hỗ trợ. Các phòng SEO kỹ thuật crawl quy mô lớn nhằm kiểm tra nội dung trùng lặp, cấu trúc tiêu đề và liên kết nội bộ phục vụ tối ưu hóa.
Giá và mô hình tính phí của firecrawl AI
firecrawl AI là dự án mã nguồn mở, cho phép sử dụng và tự lưu trữ theo giấy phép tương ứng. Nhiều nhóm triển khai trực tiếp trên hạ tầng riêng để kiểm soát chi phí và dữ liệu. Ngoài tự host, có thể tích hợp qua API/dịch vụ do nhà phát triển hoặc bên thứ ba cung cấp; mức phí, hạn mức và ưu đãi (nếu có) sẽ phụ thuộc từng nhà cung cấp dịch vụ cụ thể.
Ưu điểm và hạn chế của firecrawl AI
Ưu điểm:
- Dữ liệu “LLM‑ready” sạch, có cấu trúc, phù hợp cho RAG và tìm kiếm ngữ nghĩa.
- Hỗ trợ Markdown, JSON và ảnh chụp màn hình trong một luồng thống nhất.
- Xử lý nội dung động và cơ chế chờ thông minh giúp giảm thiếu hụt dữ liệu.
- Xoay proxy, rate limit và retry giúp tăng độ ổn định khi crawl quy mô lớn.
- Mã nguồn mở, dễ tùy biến và tích hợp vào pipeline hiện có.
- Khả năng mở rộng tốt với orchestration và thực thi song song.
Hạn chế:
- Hiệu quả phụ thuộc vào cấu trúc trang và chính sách truy cập của từng website.
- Cần cấu hình phù hợp (proxy, rate limit) để tránh lỗi và tối ưu chi phí hạ tầng.
- Xử lý nội dung động có thể tăng thời gian và tài nguyên xử lý.
- Không phải lúc nào cũng trích xuất hoàn hảo các thành phần tùy biến sâu (widget phức tạp).
- Đòi hỏi tuân thủ robots.txt và điều khoản sử dụng trang nguồn.
Câu hỏi thường gặp về firecrawl AI
-
firecrawl AI có hỗ trợ nội dung tải bằng JavaScript không?
Có. Công cụ sử dụng cơ chế chờ thông minh để xử lý trang SPA/CSR, giúp trích xuất đầy đủ hơn.
-
Có thể xuất dữ liệu ở định dạng nào?
Hỗ trợ xuất Markdown, JSON và ảnh chụp màn hình phục vụ cả NLP và kiểm chứng thủ công.
-
firecrawl AI có phù hợp cho RAG không?
Rất phù hợp. Nội dung được làm sạch và giữ cấu trúc giúp tách đoạn (chunking), lập chỉ mục và truy vấn hiệu quả.
-
Tôi có thể tự lưu trữ công cụ không?
Có. Là dự án mã nguồn mở, bạn có thể tự triển khai để kiểm soát dữ liệu, hiệu năng và chi phí.
-
Làm sao để hạn chế bị chặn khi crawl?
Thiết lập xoay proxy, giới hạn tốc độ, tôn trọng robots.txt và đặt backoff hợp lý để vận hành ổn định, tuân thủ.
-
firecrawl AI tích hợp vào quy trình hiện có như thế nào?
Thông qua API/SDK và workflow orchestration; dữ liệu đầu ra có thể đưa vào kho dữ liệu, công cụ tìm kiếm hoặc vector DB cho LLM.