firecrawl
打开网站-
工具介绍:将任意网站转为LLM可用数据;开源,支持JSON/Markdown,智能等待与代理轮换,并可输出截图,易集成现有流程。
-
收录时间:2025-10-21
-
社交媒体&邮箱:


工具信息
什么是 firecrawl AI
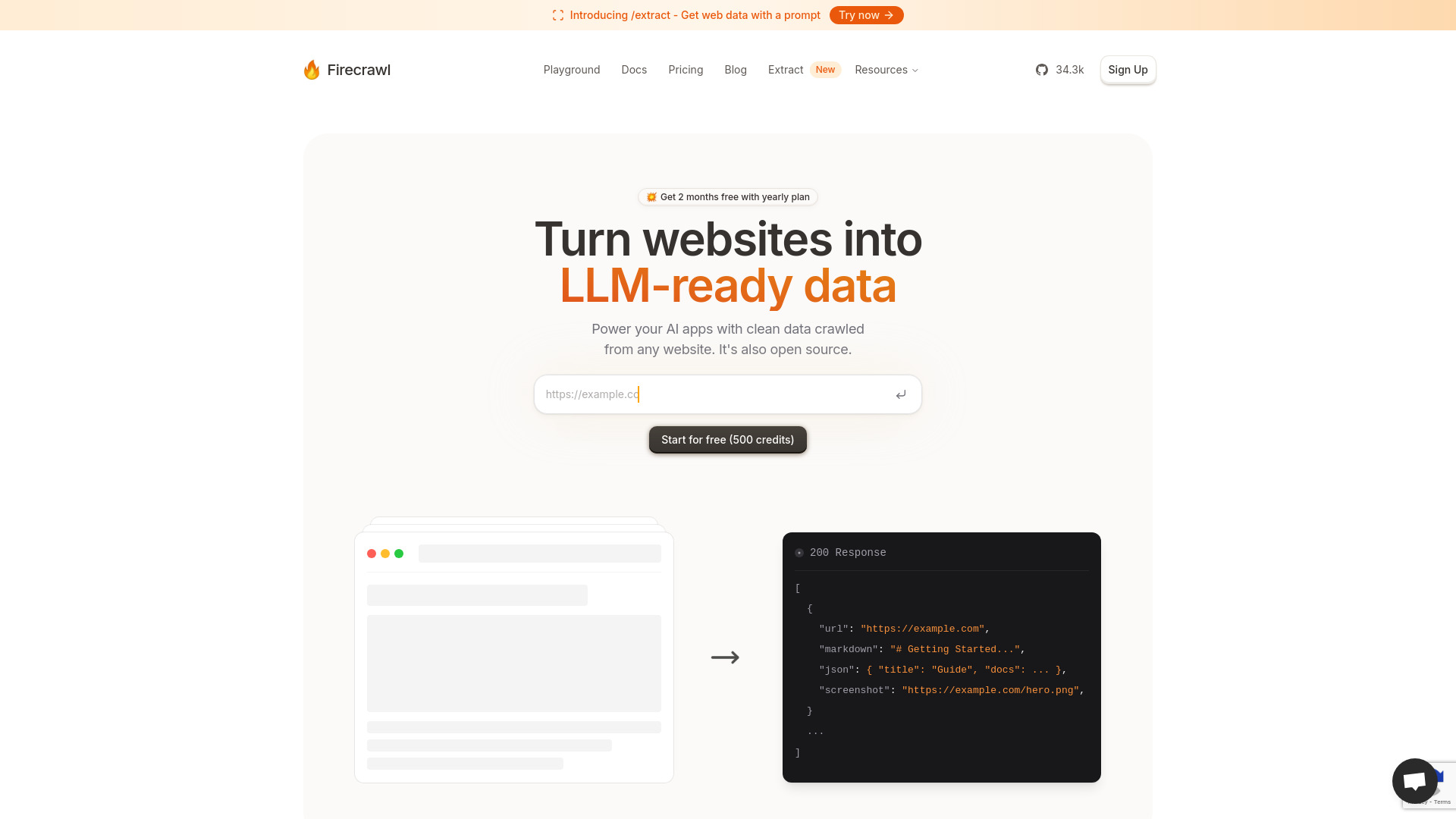
firecrawl AI 是一款面向开发者与数据团队的开源网站爬取与内容抽取工具,核心目标是把任意网站转化为可直接被大语言模型(LLM)消费的干净数据。它集成了站点爬行、网页抓取、正文提取与格式化输出等能力,能够批量从入口链接出发,按深度与规则获取页面,并将有效信息标准化为 Markdown、JSON 以及页面截图,方便后续接入向量数据库、RAG 检索增强生成和知识库构建。工具内置代理轮换、速率限制、失败重试与任务编排,能更稳健地应对限流与反爬;同时支持对动态内容的“智能等待”,在页面完成渲染后再抓取,使单页应用与懒加载场景同样可用。它还支持自定义抓取范围、黑白名单、Sitemap、请求头与延时策略,提升抓取的可控性与合规性;在清洗阶段,可抽取标题、正文、时间、链接与元数据,去噪去重,减少无关内容进入语料。对需要证据链的场景,可保存全页或区域截图,便于人工核验与标注。通过 API 与常见工作流集成,firecrawl AI 帮助团队把分散的网页内容转化为可计算的结构化数据,显著降低数据准备与工程成本。
firecrawl AI主要功能
- 网站爬行与范围控制:从起始 URL 递归抓取,支持深度限制、域名白/黑名单与 Sitemap 引导。
- 结构化内容抽取与清洗:提取标题、正文、元数据与链接,去噪去重,输出标准化 Markdown/JSON。
- 动态页面智能等待:在页面渲染完成后再抓取,适配 SPA、懒加载与异步内容。
- 截图与快照留存:支持全页或区域截图,便于数据核验、标注与审计。
- 代理轮换与反爬应对:内置代理轮换、速率限制、退避重试与错误处理,提升稳定性。
- 任务编排与并发控制:队列、并发、断点续跑与调度策略,保障大规模抓取的吞吐与可靠性。
- 工作流与生态集成:通过 API 接入 RAG 管道、向量数据库与 ETL 流水线,融入现有数据栈。
- 可配置的礼貌抓取:自定义请求头、延时、并可按需遵循站点抓取规范,兼顾效率与合规。
firecrawl AI适用人群
firecrawl AI 适合需要将网页内容转化为可用语料的数据工程与 AI 团队、构建 RAG 知识库与搜索系统的开发者、希望自动化汇聚行业资讯与竞品动态的产品与增长团队、开展资料收集与信息整合的研究与咨询机构,以及希望为客服机器人与分析模型持续供给高质量 LLM-ready 数据的企业用户。
firecrawl AI使用步骤
- 选择部署方式(自托管或托管服务),完成安装与基础配置,获取 API 密钥。
- 设定起始 URL 与抓取范围(深度、域名限制、Sitemap),明确目标页面集合。
- 配置输出格式与抽取字段(如 Markdown、JSON、截图),定义清洗与去重规则。
- 按需开启动态渲染与智能等待参数,确保异步内容加载后再抓取。
- 设置并发、速率限制、代理池与重试策略,平衡效率与稳定性。
- 启动爬行任务,监控日志与指标,遇到异常根据提示调整策略。
- 导出结果并接入向量数据库或 RAG 流水线,制定周期性或增量抓取计划。
firecrawl AI行业案例
在 SaaS 领域,团队可批量抓取帮助中心与文档站,清洗为统一 Markdown/JSON,快速构建客服问答知识库;电商与零售可采集商品详情、规格与常见问答,定期更新以支持比价监测与产品检索;媒体与舆情分析场景中,通过抓取新闻稿与栏目页,构建主题语义索引与溯源截图库;教育与科研机构可汇聚公开教材、博客与论文摘要,将其接入向量数据库,提升检索增强生成的覆盖与准确性。
firecrawl AI收费模式
firecrawl AI 以开源形态提供,适合自托管与私有部署;如选择官方或生态中的云端托管/API 服务,通常按抓取量、并发或功能分级计费,常见提供一定的免费额度或试用期,具体方案与价格以官方渠道为准。
firecrawl AI优点和缺点
优点:
- 开源可控,支持自托管,便于数据合规与隐私治理。
- 输出标准化(Markdown/JSON/截图),可直接进入 LLM、向量库与 RAG 流程。
- 智能等待与动态渲染,提高对复杂前端站点的抓取成功率。
- 代理轮换、速率限制与重试机制,适合持续稳定的规模化采集。
- API 友好,易于融入现有数据管道与工程体系。
缺点:
- 大规模抓取仍依赖高质量代理与 IP 资源,运维成本不可忽视。
- 面对强反爬与频繁变更的站点,可能需要定制策略或人工校验。
- 动态渲染带来额外计算开销与时间成本,需合理调参。
- 跨网站的一致性抽取需持续调优模板与规则。
firecrawl AI热门问题
-
问题 1: 支持哪些输出格式?
支持将页面内容导出为 Markdown、JSON,并可保存页面截图以便复核与存档。
-
问题 2: 能否处理动态渲染与单页应用?
可以。通过智能等待与渲染后抓取机制,适配 SPA、懒加载与异步请求场景。
-
问题 3: 如何应对限流与封禁?
可启用代理轮换、速率限制与退避重试,并调整并发与请求头策略以提升稳定性。
-
问题 4: 是否开源,能自托管吗?
是。作为开源工具,支持本地或私有环境部署,便于合规与数据控制。
-
问题 5: 能与 RAG 与向量数据库集成吗?
可以。将抽取文本送入嵌入与索引流程,即可用于检索增强生成与语义搜索。
-
问题 6: 是否支持增量更新?
可通过配置抓取范围、更新时间过滤与去重策略,减少重复抓取并实现周期性增量刷新。