Synexa
Mở trang web-
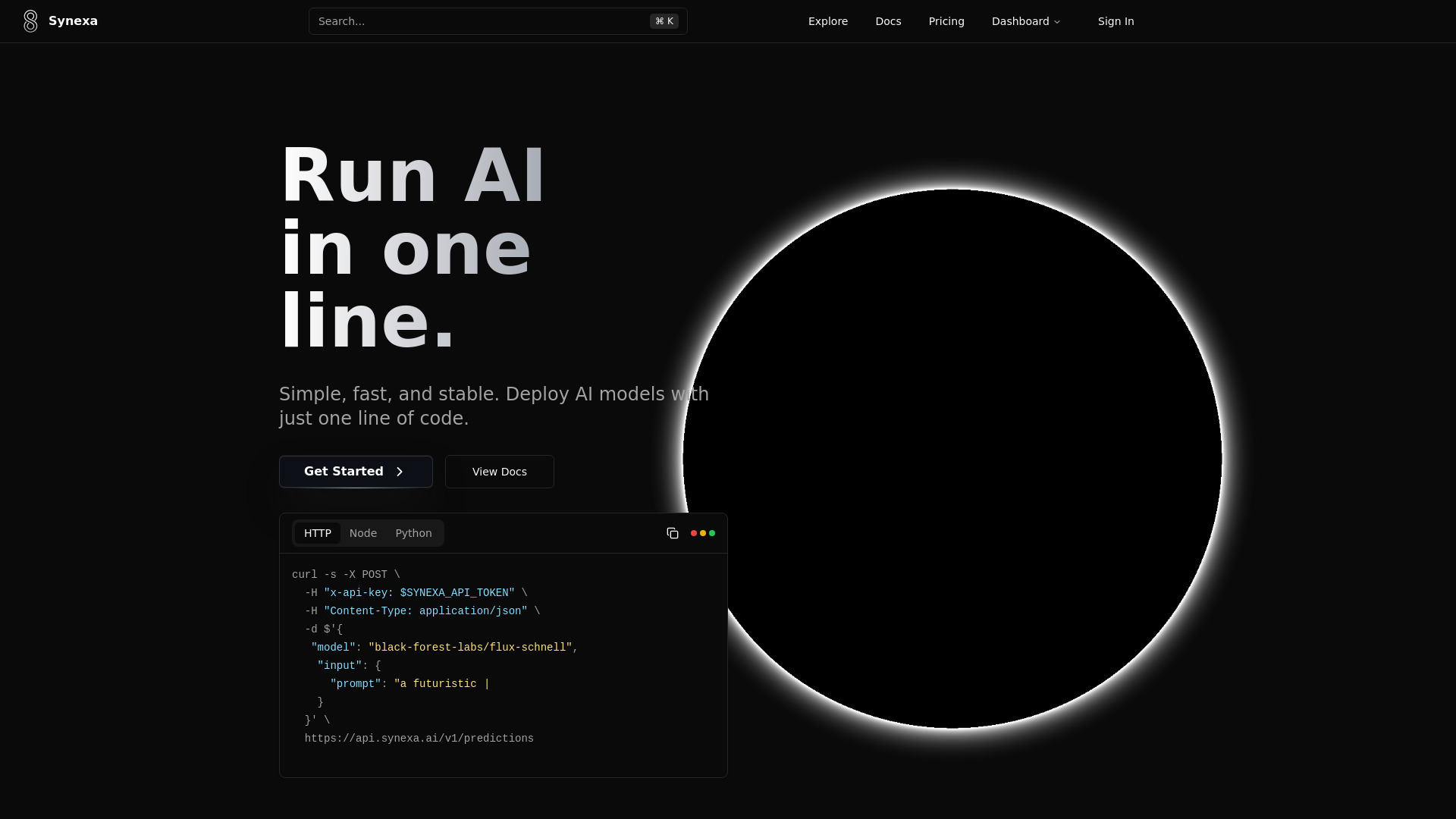
Giới thiệu công cụ:Synexa AI: 1 dòng chạy 100+ mô hình; suy luận nhanh, GPU rẻ, autoscale.
-
Ngày thêm:2025-10-28
-
Mạng xã hội & Email:
Thông tin công cụ
Synexa AI là gì?
Synexa AI là nền tảng triển khai và hạ tầng AI giúp bạn chạy các mô hình AI mạnh mẽ chỉ với một dòng code. Được thiết kế cho tốc độ, độ ổn định và trải nghiệm thân thiện với lập trình viên, Synexa tối ưu chi phí với giá GPU cạnh tranh và khả năng tự động mở rộng theo tải. Nền tảng cung cấp thư viện hơn 100 mô hình sẵn sàng cho môi trường sản xuất, đi kèm inference engine cực nhanh để rút ngắn thời gian từ ý tưởng đến sản phẩm. Dù bạn đang thử nghiệm MVP hay vận hành hệ thống ở quy mô lớn, Synexa AI giúp đơn giản hóa toàn bộ vòng đời suy luận, giảm gánh nặng hạ tầng và tăng tốc tích hợp vào ứng dụng thực tế.
Các tính năng chính của Synexa AI
- Chạy mô hình bằng 1 dòng code: quy trình tích hợp đơn giản, giảm tối đa thời gian khởi chạy.
- Hơn 100 mô hình sẵn sàng production: đa dạng nhu cầu từ xử lý ngôn ngữ, thị giác máy tính đến âm thanh.
- Inference engine tốc độ cao: độ trễ thấp, thông lượng cao cho khối lượng yêu cầu lớn.
- Tự động mở rộng (auto scaling): thích ứng linh hoạt theo lưu lượng, không cần quản lý máy chủ.
- Hạ tầng ổn định, hướng tới sản xuất: tối ưu vận hành cho dịch vụ trực tuyến 24/7.
- Giá GPU hiệu quả: tối ưu chi phí suy luận theo nhu cầu sử dụng thực tế.
- Trải nghiệm nhà phát triển đẳng cấp: quy trình rõ ràng, tài liệu dễ tiếp cận, tích hợp nhanh vào ứng dụng.
Đối tượng phù hợp với Synexa AI
Synexa AI phù hợp với startup cần ra mắt tính năng AI nhanh, đội ngũ sản phẩm muốn tích hợp mô hình vào ứng dụng web/mobile, nhóm kỹ sư dữ liệu – machine learning ưu tiên suy luận ổn định với chi phí hợp lý, và doanh nghiệp muốn mở rộng dịch vụ AI mà không đầu tư hạ tầng GPU phức tạp. Công cụ cũng hữu ích cho hackathon, POC, MVP đến các hệ thống production có lưu lượng biến động.
Cách sử dụng Synexa AI
- Tạo tài khoản và nhận thông tin truy cập cần thiết (ví dụ: khóa API).
- Chọn mô hình từ danh mục hơn 100 mô hình sẵn sàng sử dụng.
- Sao chép “một dòng code” do nền tảng cung cấp và cấu hình tham số suy luận cơ bản.
- Tích hợp vào backend, dịch vụ hoặc ứng dụng của bạn thông qua API/SDK phù hợp.
- Kiểm thử kết quả, tối ưu prompt/tham số và điều chỉnh cấu hình hiệu năng.
- Kích hoạt tự động mở rộng để đáp ứng lưu lượng thực tế và theo dõi mức sử dụng.
Trường hợp ứng dụng thực tế của Synexa AI
Doanh nghiệp thương mại điện tử triển khai phân loại sản phẩm và tìm kiếm thông minh; bộ phận chăm sóc khách hàng tích hợp chatbot, tóm tắt hội thoại; nền tảng nội dung dùng nhận dạng hình ảnh để kiểm duyệt; ứng dụng truyền thông chuyển giọng nói thành văn bản; quy trình nội bộ tự động hóa trích xuất thông tin tài liệu. Với thư viện mô hình phong phú và inference nhanh, Synexa AI giúp rút ngắn thời gian triển khai, đảm bảo hiệu năng và kiểm soát chi phí.
Gói cước và mô hình giá của Synexa AI
Synexa AI áp dụng mô hình giá GPU hiệu quả nhằm tối ưu chi phí suy luận cho người dùng. Chi phí thường được tính dựa trên tài nguyên sử dụng (thời gian chạy, loại GPU, khối lượng yêu cầu), giúp bạn dễ dàng kiểm soát ngân sách theo dự án hoặc sản phẩm. Người dùng có thể bắt đầu nhỏ, mở rộng theo nhu cầu mà không cần đầu tư trước vào hạ tầng phần cứng.
Ưu điểm và nhược điểm của Synexa AI
Ưu điểm:
- Khởi chạy mô hình cực nhanh chỉ với một dòng code.
- Inference engine tốc độ cao, độ trễ thấp.
- Tự động mở rộng, vận hành ổn định cho môi trường production.
- Kho hơn 100 mô hình sẵn sàng, đáp ứng nhiều kịch bản phổ biến.
- Giá GPU tối ưu, linh hoạt theo mức sử dụng.
- Trải nghiệm thân thiện với lập trình viên, dễ tích hợp vào ứng dụng.
Nhược điểm:
- Phụ thuộc vào hạ tầng đám mây của nhà cung cấp.
- Mức độ tùy biến hạ tầng thấp hơn so với tự triển khai trên máy chủ riêng.
- Chi phí có thể tăng nếu lưu lượng suy luận lớn và liên tục.
- Danh mục mô hình sẵn có có thể không phù hợp với một số nhu cầu đặc thù.
Các câu hỏi thường gặp về Synexa AI
-
Câu hỏi: Synexa AI hỗ trợ những loại mô hình nào?
Trả lời: Nền tảng cung cấp hơn 100 mô hình sẵn sàng cho sản xuất, bao phủ các tác vụ phổ biến như xử lý ngôn ngữ tự nhiên, thị giác máy tính và âm thanh/giọng nói.
-
Câu hỏi: Tôi có cần tự quản lý GPU không?
Trả lời: Không. Synexa AI cung cấp hạ tầng GPU với giá hiệu quả, bạn chỉ cần gọi mô hình qua một dòng code và trả phí theo mức sử dụng.
-
Câu hỏi: Synexa AI có tự động mở rộng theo tải không?
Trả lời: Có. Khả năng auto scaling giúp hệ thống đáp ứng lưu lượng biến động mà không cần cấu hình phức tạp.
-
Câu hỏi: Hiệu năng suy luận như thế nào?
Trả lời: Synexa AI sử dụng inference engine tốc độ cao nhằm giảm độ trễ và tăng thông lượng, phù hợp cho ứng dụng thời gian thực và khối lượng yêu cầu lớn.
-
Câu hỏi: Mất bao lâu để tích hợp vào ứng dụng?
Trả lời: Nhờ quy trình triển khai bằng một dòng code và tài liệu rõ ràng, bạn có thể bắt đầu chạy mô hình và tích hợp vào dịch vụ hiện có chỉ trong thời gian rất ngắn.