Synexa
Site web ouvert-
Présentation de l'outil:Synexa AI: déployez 100+ modèles en 1 ligne, GPU et autoscaling.
-
Date d'inclusion:2025-10-28
-
Réseaux sociaux et e-mails:
Informations sur l'outil
Qu’est-ce que Synexa AI
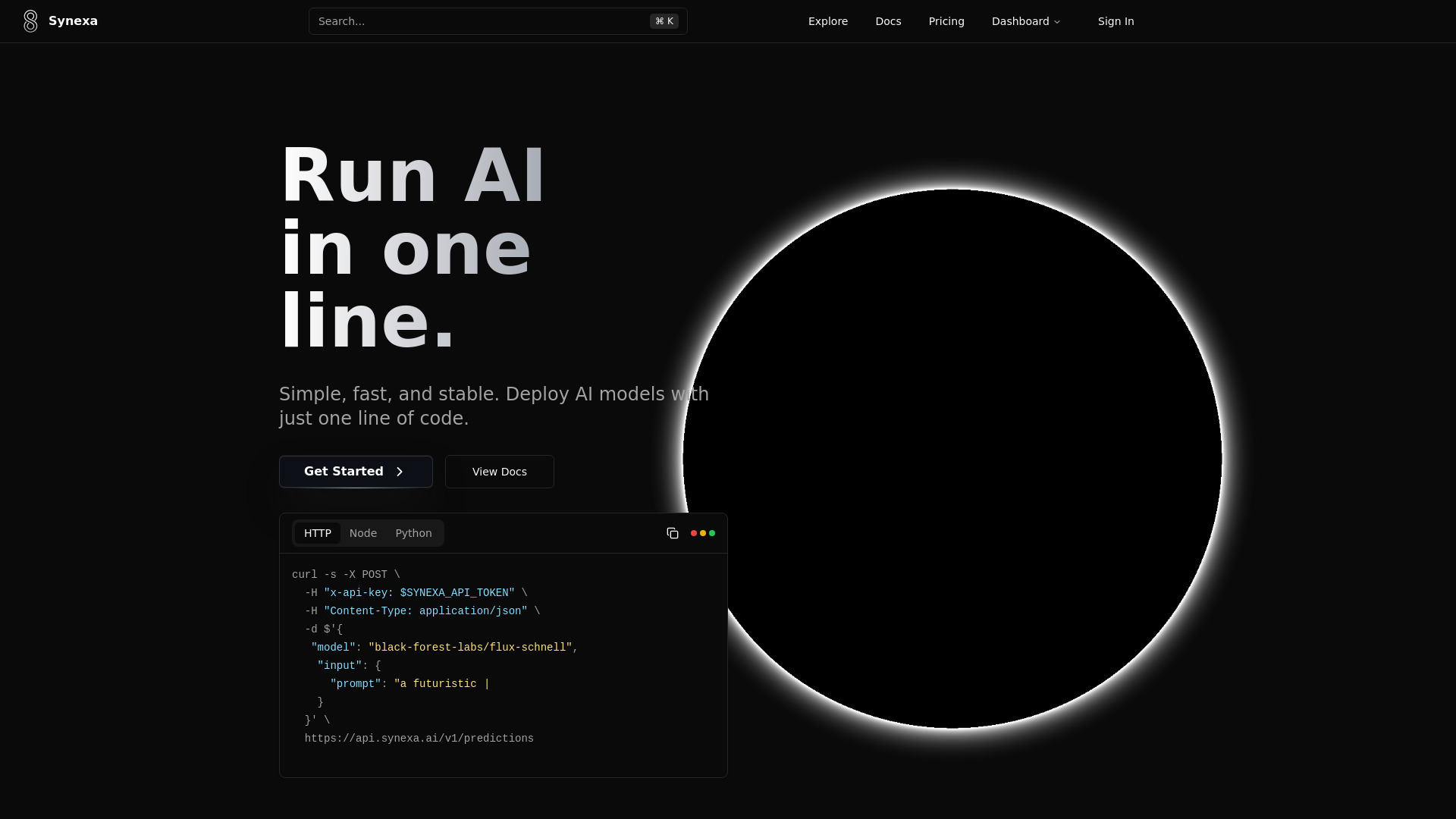
Synexa AI est une plateforme de déploiement d’IA et d’infrastructure conçue pour exécuter des modèles puissants en quelques instants, avec une seule ligne de code. Pensée pour la rapidité et la stabilité, elle offre une expérience développeur fluide, une tarification GPU optimisée et une scalabilité automatique pour absorber les pics de charge sans effort. Synexa met à disposition un vaste catalogue de plus de 100 modèles prêts pour la production et s’appuie sur un moteur d’inférence à très faible latence afin d’accélérer le passage du prototype à la mise en production.
Fonctionnalités principales de Synexa AI
- Déploiement en une ligne de code : intégration rapide dans vos applications sans lourde configuration.
- Catalogue de 100+ modèles : accès immédiat à des modèles d’IA prêts pour la production pour le texte, la vision et d’autres cas.
- Moteur d’inférence ultrarapide : latence réduite pour des réponses en temps réel et des expériences utilisateurs fluides.
- Scalabilité automatique : montée en charge sans intervention manuelle selon le trafic et la demande.
- Tarification GPU optimisée : exécution rentable des charges de travail intensives en calcul.
- Stabilité et fiabilité : infrastructure pensée pour les environnements de production.
- Expérience développeur soignée : flux d’intégration simplifiés et utilisation intuitive.
- Prête pour la production : modèles et services conçus pour des SLA exigeants et un passage en production accéléré.
À qui s’adresse Synexa AI
Synexa AI s’adresse aux développeurs d’applications, équipes produit, data scientists et ingénieurs MLOps/DevOps souhaitant déployer des modèles à grande échelle avec une latence faible et des coûts GPU maîtrisés. Elle convient aux startups qui veulent itérer vite, aux PME en quête d’une infrastructure IA fiable, ainsi qu’aux grandes entreprises nécessitant une inférence stable et évolutive en production.
Comment utiliser Synexa AI
- Créer un compte et configurer votre espace de travail.
- Choisir un modèle parmi le catalogue de plus de 100 options prêtes pour la production.
- Définir les paramètres d’inférence (taille de sortie, seuils, ressources GPU, etc.).
- Intégrer le point d’accès via une seule ligne de code dans votre application.
- Lancer en production : la scalabilité automatique ajuste les ressources selon la charge.
- Surveiller performance et coûts (latence, débit, consommation GPU) et optimiser selon les besoins.
Cas d’utilisation de Synexa AI
Support client conversationnel avec des modèles de langage, génération et résumé de contenus, recherche sémantique et embeddings, modération et classification de texte, analyse d’images pour contrôle qualité, extraction d’informations de documents, recommandations personnalisées en temps réel, ainsi que traitement audio pour transcription et analyse.
Tarification de Synexa AI
Synexa AI met en avant une tarification GPU conçue pour être coût‑efficace. Les modalités détaillées (paliers, conditions et éventuelles offres) ne sont pas précisées ici. Pour connaître la grille tarifaire à jour, veuillez consulter la page officielle du service.
Avantages et inconvénients de Synexa AI
Avantages :
- Déploiement extrêmement rapide via une seule ligne de code.
- Plus de 100 modèles prêts pour la production.
- Inférence à faible latence et haute stabilité.
- Scalabilité automatique intégrée.
- Tarification GPU optimisée pour réduire les coûts.
- Expérience développeur fluide et gain de temps jusqu’à la mise en production.
Inconvénients :
- Dépendance à une plateforme tierce pour l’infrastructure d’IA.
- Moins de contrôle fin sur l’environnement que sur une pile entièrement auto‑hébergée.
- Les coûts peuvent augmenter avec des charges très élevées selon l’usage.
- Le support de modèles spécifiques ou de personnalisations avancées peut varier.
Questions fréquentes sur Synexa AI
-
Synexa AI permet‑il vraiment de déployer en une seule ligne de code ?
Oui, la plateforme est conçue pour une intégration rapide afin d’exécuter des modèles immédiatement avec un minimum d’effort.
-
Quels types de modèles sont disponibles ?
Un large éventail de modèles prêts pour la production est proposé (texte, vision et autres usages), avec plus de 100 options accessibles.
-
Comment la montée en charge est‑elle gérée ?
La scalabilité automatique ajuste les ressources en fonction de la demande pour maintenir la performance et la stabilité.
-
Quelle est la performance d’inférence ?
Synexa AI s’appuie sur un moteur d’inférence très rapide conçu pour offrir une latence minimale en production.
-
Où trouver les informations de tarification ?
Les détails de tarification sont disponibles sur le site officiel de Synexa AI et peuvent évoluer selon l’usage et les ressources GPU.