Airbyte
打开网站-
工具介绍:开源ELT数据集成:即插即用连接器,数据库/API复制,AI就绪。支持云/自托管/混合,保障数据安全治理,可嵌入式连接器
-
收录时间:2025-10-21
-
社交媒体&邮箱:




工具信息
什么是 Airbyte
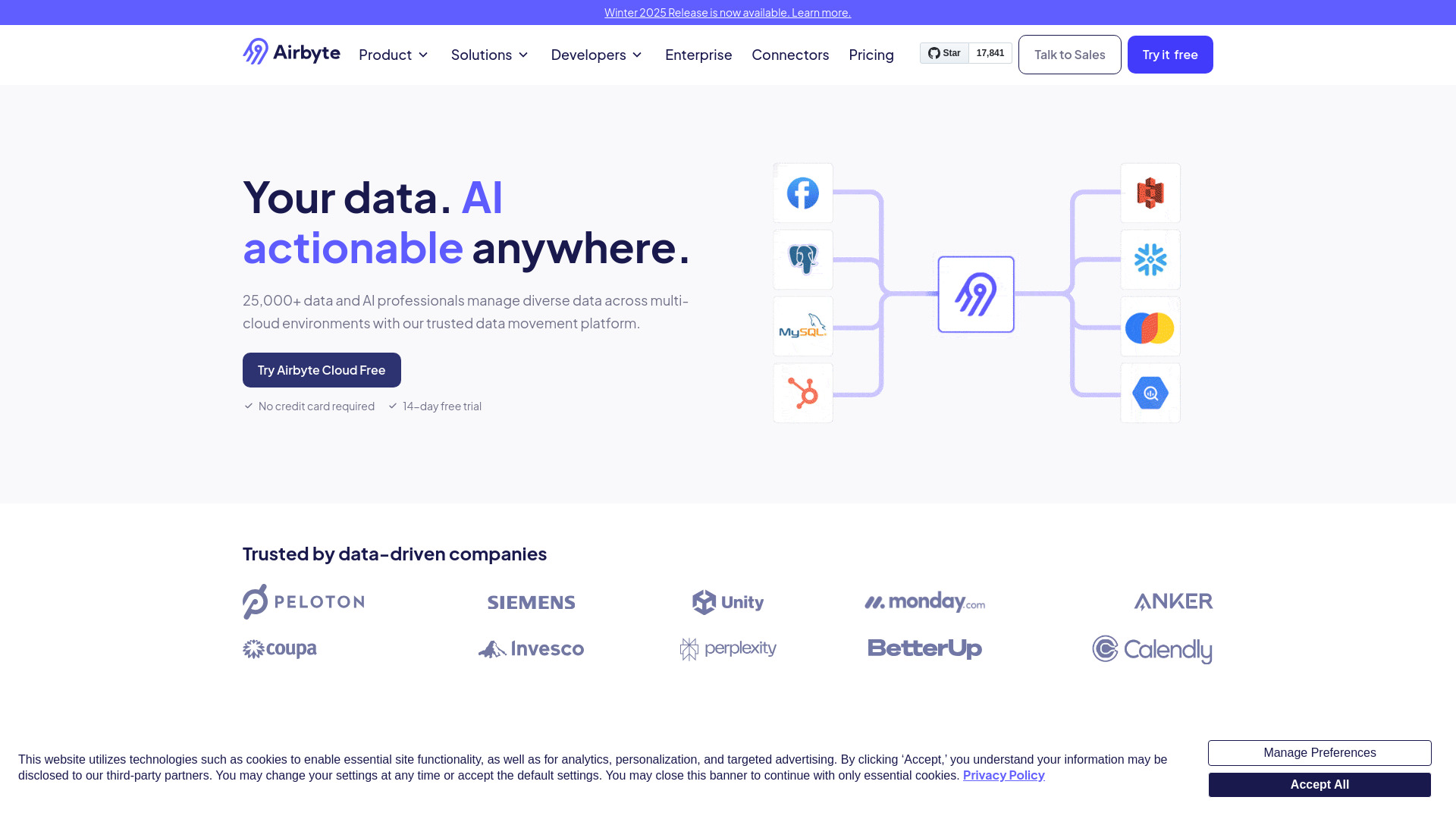
Airbyte 是一款面向现代数据栈的开源数据集成与抽取‑加载‑转换平台,帮助团队在不同系统之间稳定、可扩展地同步数据。它支持从数据库、文件存储与各类应用编程接口获取数据,进行可靠复制与标准化处理,再加载至数据仓库、数据湖、操作型数据库或向量数据库,为分析报表、业务应用以及人工智能与大语言模型提供可直接使用的数据基础。借助可嵌入的连接器与组件化架构,Airbyte 既能满足快速接入的通用需求,也能通过自定义开发适配长尾或私有数据源。它同时支持自托管、云端与混合部署,兼顾弹性与合规,在保障数据安全与治理的前提下,降低数据管道的建设与维护成本,加速企业的数据驱动与智能化落地。
Airbyte主要功能
- 丰富的连接器生态:覆盖常见数据库、应用编程接口与文件存储等来源与目标,支持快速对接并可按需扩展自定义连接器。
- 稳定的数据复制:提供全量与增量同步、变更数据捕获等模式,支持断点续传与失败重试,确保在大规模场景下依然可靠。
- 抽取‑加载‑转换流程:先加载后转换的设计,结合轻量标准化与字段映射,减少上游耦合,便于在仓库或湖仓侧统一治理。
- 调度与可观测性:内置任务调度、日志与指标监控,配合告警与运行历史,便于排障与容量规划。
- 面向人工智能的数据准备:支持将文本与业务数据整理后加载到向量数据库,便于构建检索增强生成等智能应用。
- 安全与治理:支持密钥管理、权限控制与审计记录,配合分环境与混合部署,满足企业对数据安全与合规的要求。
- 可嵌入与二次开发:通过组件化接口将连接能力嵌入自家产品或内部平台,统一数据接入体验。
Airbyte适用人群
适合数据工程师与分析工程师搭建跨源数据管道;适合人工智能与应用开发团队为知识库与智能问答准备高质量数据;适合商业分析与运营团队整合营销、销售、客服与财务数据做统一分析;也适合需要跨地域数据库复制、容灾与读写分离的技术团队,以及期望在自托管与云端之间灵活选择的合规敏感型组织。
Airbyte使用步骤
- 选择部署方式:在自托管环境安装,或注册云端与混合部署以快速上手。
- 新建连接:选择数据来源与目标(如数据库、数据仓库、对象存储或向量数据库)。
- 配置凭据与权限:填写地址、账号、密钥等敏感信息,并进行最小权限授权。
- 选择同步范围:勾选库表或接口资源,设置字段映射与数据类型策略。
- 设定同步模式:按需选择全量、增量或变更数据捕获,并配置去重与合并规则。
- 设置调度与性能:配置运行频率、并发与批量大小,启用告警与通知。
- 启用标准化与转换:根据需要进行轻量清洗与规范化,保持下游一致的模式。
- 试运行与验证:执行测试同步,核对记录数、示例数据与目标表结构。
- 上线与监控:在生产环境启用任务,持续查看日志、指标与告警,按需扩容与优化。
Airbyte行业案例
电商与零售:将交易、库存与营销投放数据汇入数据仓库,构建客户与商品全景分析。金融与互联网服务:基于变更数据捕获实现跨库复制与审计留痕,支持风控报表与合规监管。制造与物联网:汇聚设备遥测与维护记录至湖仓,用于预测性维护与产能优化。企业软件与运营:整合客服工单、知识文档与使用日志,加载至向量数据库,驱动检索增强生成的智能客服与内部知识检索。跨区域业务:将主库数据复制到只读副本,降低延迟并提升容灾能力。
Airbyte收费模式
Airbyte 提供开源自托管版本,可免费部署与二次开发;同时提供云端与企业级服务,通常依据使用量(如同步数据规模、任务运行频次或连接数量)计费,并可能提供免费额度或试用以便评估。针对有更高安全、合规与支持需求的组织,可选择企业支持与服务等级保障,具体方案与价格以官方发布与商务沟通为准。
Airbyte优点和缺点
优点:
- 开源与可扩展,连接器生态丰富,易于自定义开发与嵌入。
- 支持增量与变更数据捕获,适配从小规模到大规模的稳定同步。
- 部署灵活,覆盖自托管、云端与混合场景,便于满足合规与成本控制。
- 面向人工智能的数据准备能力完善,便于构建检索增强生成等应用。
- 良好的调度、监控与可观测性,便于运维与故障排查。
缺点:
- 自托管需要投入运维与监控,对团队基础设施能力有要求。
- 部分长尾连接器可能需二次开发或调优,初期集成成本较高。
- 以先加载后转换为主,复杂业务规则往往需要在下游统一治理与计算。
- 低延迟的实时流式场景需要谨慎评估吞吐与延迟目标。
Airbyte热门问题
-
问题 1:
Airbyte 能否支持企业级的数据安全与合规?
-
回答:
支持。可通过自托管与混合部署将数据留在自有环境,配合权限控制、密钥管理与审计记录,满足多数安全与合规要求;云端版本通常也提供相应的安全与治理能力。
-
问题 2:
如何处理增量与变更数据捕获场景?
-
回答:
在创建连接时选择增量或变更数据捕获模式,配置主键与水位字段或日志来源,并在目标端设置去重与合并策略,既减少同步量又保持数据一致性。
-
问题 3:
是否适合为大语言模型准备知识库数据?
-
回答:
适合。可将文档、网页与业务数据抽取、清洗后加载至向量数据库或检索系统,构建检索增强生成流程,用于智能客服、搜索与内容生成。
-
问题 4:
与传统全功能数据集成套件相比有什么优势?
-
回答:
开源与组件化带来更高的灵活性与可扩展性,部署与成本可控;连接器生态与社区迭代快,能更快覆盖新兴数据源与目标。
-
问题 5:
如何降低运维成本与故障率?
-
回答:
建议分环境部署、启用告警与重试、合理设置批量与并发、定期校验模式变化,并对关键任务设置资源隔离与容量预留,以提升稳定性与可用性。