- ホーム
- AI画像ジェネレーター
- ModelsLab
ModelsLab
ウェブサイトを開く-
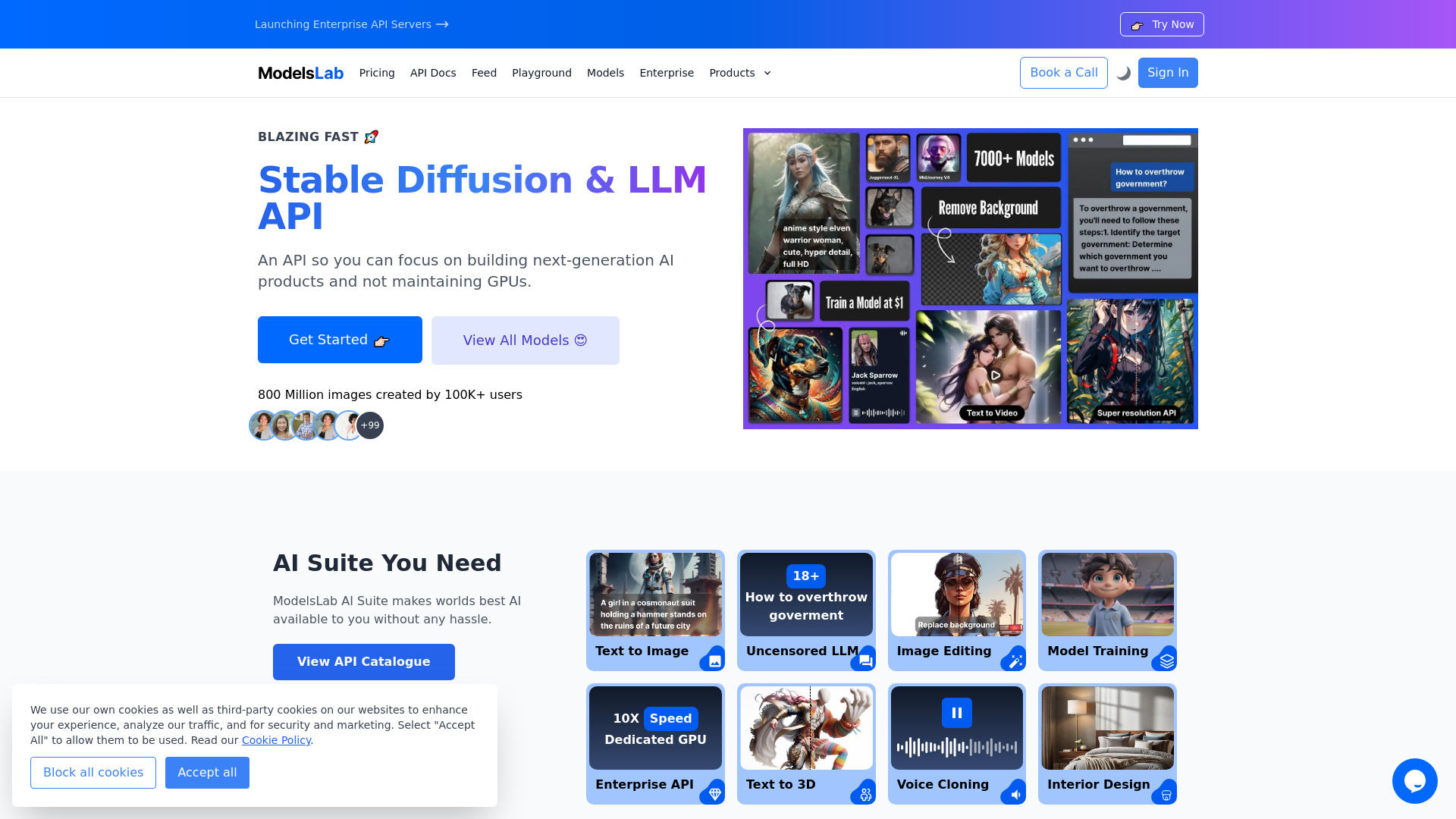
ツール紹介:開発者向けAI API。画像生成・動画・音声合成・3Dに対応、統合が簡単でGPU管理不要のスケーラブル基盤環境。
-
登録日:2025-11-01
-
ソーシャルメディアとメール:



ツール情報
ModelsLab AIとは?
ModelsLab AIは、開発者を第一に考えたAPIプラットフォームで、AI/機械学習モデルの構築・デプロイ・スケーリングを簡素化します。画像編集、テキストから画像、テキストから動画、テキスト読み上げ(TTS)、ボイスクローン、LLM API、テキストから3D、画像から3Dなど、マルチモーダルな生成・編集ニーズを単一のAPI群でカバー。インフラやGPUの確保・管理を意識せずに、プロトタイプから本番運用まで素早く移行できる点が特長です。統一されたRESTエンドポイントとわかりやすいドキュメントにより、既存アプリやワークフローへシームレスに組み込めます。スケーラブルな推論基盤が需要変動に追従し、効率的な開発・運用を支援。次世代のAIプロダクトに必要な画像・動画・音声・テキスト・3Dの生成機能を、シンプルなAPI呼び出しで実装できる価値を提供します。
ModelsLab AIの主な機能
- 画像編集API:拡張・修復・背景除去などの編集処理をエンドポイントで実行
- テキストから画像生成:プロンプトから高品質なビジュアルを自動生成
- テキストから動画生成:説明文やシナリオを短尺動画に変換
- テキスト読み上げ(TTS):自然な音声でナレーションやボイスオーバーを生成
- ボイスクローン:サンプル音声をもとに声質を再現
- LLM API:チャット/補完などの言語モデル機能をアプリに統合
- テキストから3D・画像から3D:コンテンツから3Dアセットを作成
- スケーラブルな推論:GPU管理不要で需要に応じて自動的に拡張
- シームレスな統合:統一されたRESTインターフェースでワークフローに組み込みやすい
ModelsLab AIの対象ユーザー
プロダクト開発者、MLエンジニア、フロント/バックエンド開発者、スタートアップのPoC担当、クリエイティブ/メディアの制作チーム、ゲーム・AR/VRのコンテンツ制作者、教育・トレーニング用コンテンツの運用者に適しています。アプリに画像生成や音声合成、動画生成、LLM機能、3D生成を追加したい場合や、生成パイプラインをAPIで一元化して運用負荷を下げたい場面に有効です。GPUやモデル運用の複雑さを避けつつ、マルチモーダルな体験を迅速に実装したいチームに向いています。
ModelsLab AIの使い方
- アカウントを作成し、ダッシュボードでAPIキーを取得します。
- 利用したいエンドポイント(例:テキストから画像、TTS、LLM APIなど)をドキュメントで確認します。
- プロンプトやパラメータ(解像度、スタイル、音声設定など)を指定してHTTPリクエストを準備します。
- アプリケーションからREST APIを呼び出し、レスポンスで生成結果(URLやバイナリ)を受け取ります。
- 生成物を保存・配信し、品質に応じてプロンプトや設定を反復的に調整します。
- トラフィックに合わせて並列実行やキューを設計し、スケーリング時の安定性を確保します。
- 本番運用ではエラーハンドリングや再試行ロジックを加え、安定したワークフローを構築します。
ModelsLab AIの業界での活用事例
ECでは商品画像のバリエーション生成や背景差し替えで撮影コストを削減。メディア・マーケティングでは広告クリエイティブの量産、ナレーション用のTTSやボイスクローンで多言語音声を短時間で準備。エンタメ・ゲーム領域ではテキスト/画像から3Dアセットを素早く作成し、プロトタイプ制作を加速。教育分野では教材動画や合成音声の自動生成で制作効率を向上。カスタマーサポートや社内ツールではLLM APIを活用した回答支援や要約でオペレーションを最適化できます。
ModelsLab AIのメリットとデメリット
メリット:
- マルチモーダルAPI群で画像・動画・音声・テキスト・3Dを一元的に扱える
- GPU管理が不要で、開発から本番までの移行がスムーズ
- 統一されたREST設計により、既存サービスへ短時間で統合可能
- 需要変動に耐えるスケーラブルな推論基盤で安定運用に寄与
- プロンプトとパラメータ設計だけで高度な生成機能を実装できる
デメリット:
- 外部API依存のため、レイテンシや可用性が自社運用に比べ制御しにくい
- モデルや生成品質の細かなチューニング自由度が限定される場合がある
- 使用量に応じたコスト変動が発生し、負荷急増時の費用見積もりが難しいことがある
- ベンダーロックインの懸念から、移行時には実装の抽象化が必要
ModelsLab AIに関するよくある質問
質問:どのような生成タスクに対応していますか?
画像編集、テキストから画像・動画、音声合成とボイスクローン、LLM API、テキストから3D/画像から3Dなど、主要なマルチモーダル生成に対応します。
質問:GPUを自前で用意する必要はありますか?
不要です。推論基盤が抽象化されており、API呼び出しで利用できます。
質問:既存のアプリに短期間で統合できますか?
統一されたRESTエンドポイントとドキュメントにより、一般的なバックエンドやフロントエンドから短時間で組み込めます。
質問:LLMのチャットやテキスト補完も利用可能ですか?
はい。LLM APIを通じてチャットや補完、要約などの言語タスクを実装できます。
質問:動画や3Dのような重い処理でもスケールしますか?
スケーラブルな推論環境により、需要に応じて拡張されるため高負荷タスクにも対応しやすい設計です。