- Trang chủ
- AI Tổng hợp giọng nói
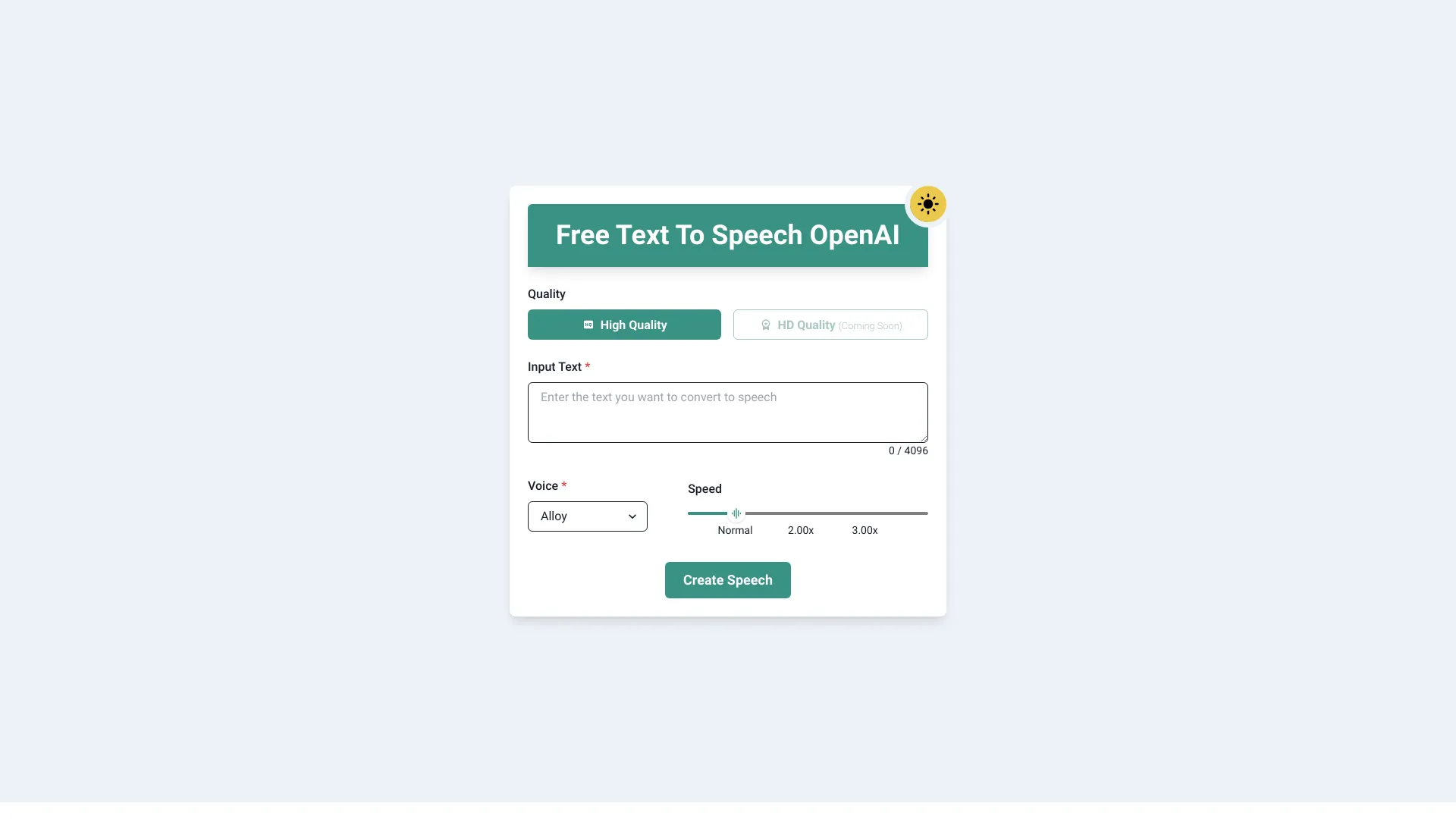
- Text To Speech OpenAI
Text To Speech OpenAI
Mở trang web-
Giới thiệu công cụ:[Biến PDF, eBook thành sách nói/MP3 giọng tự nhiên. API TTS dễ tích hợp.]
-
Ngày thêm:2025-10-28
-
Mạng xã hội & Email:

Thông tin công cụ
Text To Speech OpenAI là gì?
Text To Speech OpenAI là nền tảng chuyển văn bản thành giọng nói (Text-to-Speech) giúp bạn biến PDF, eBook và tài liệu số thành AudioBook sinh động hoặc tệp MP3 chất lượng cao. Sở hữu Voice Engine tiên tiến với chất giọng tự nhiên, nhịp điệu mượt mà và phát âm chuẩn, công cụ giúp rút ngắn thời gian sản xuất sách nói, podcast học tập và nội dung âm thanh đa định dạng. Dành cho nhà phát triển, nhà sáng tạo và doanh nghiệp, nền tảng cung cấp API trực quan để tích hợp nhanh vào ứng dụng, website, LMS hay quy trình nội bộ, nâng cao khả năng tiếp cận nội dung và tối ưu trải nghiệm người dùng trên mọi thiết bị.
Các tính năng chính của Text To Speech OpenAI
- Chuyển đổi PDF/eBook thành AudioBook: Nhập PDF/ePub/Docx và xuất âm thanh liền mạch cho sách nói hoặc podcast.
- Giọng đọc tự nhiên nhờ Voice Engine: Nhấn nhá, ngắt nghỉ, nhịp điệu gần với giọng người để nghe lâu không mệt.
- Đa giọng & đa ngôn ngữ: Nhiều phong cách giọng (trang trọng, thân mật, thuyết minh…), hỗ trợ nhiều ngôn ngữ và biến thể địa phương.
- Tùy chỉnh linh hoạt: Điều chỉnh tốc độ, cao độ, âm lượng; hỗ trợ thẻ SSML để kiểm soát phát âm, ngắt quãng, nhấn mạnh.
- Xuất âm thanh phổ biến: Tải về MP3, WAV, M4A; tối ưu bitrate để cân bằng chất lượng và dung lượng.
- Xử lý hàng loạt: Tự động hóa chuyển đổi nhiều chương/tệp, ghép chương và tạo mục lục audio.
- API dễ tích hợp: REST API/SDK giúp nhúng TTS vào ứng dụng, CMS, LMS, chatbot, IVR và quy trình nội bộ.
- Phát trực tuyến & xem trước: Nghe thử tức thì trước khi xuất bản để tinh chỉnh tham số nhanh chóng.
- Quản lý thư viện & phiên bản: Lưu, tổ chức, cập nhật và tái sử dụng dự án âm thanh theo nhu cầu.
- Phân tích sử dụng: Theo dõi thời lượng, ký tự tiêu thụ và hiệu suất để tối ưu chi phí.
Đối tượng phù hợp với Text To Speech OpenAI
Phù hợp cho tác giả và nhà xuất bản muốn tạo audiobook nhanh; nhà sáng tạo nội dung, YouTuber, podcaster cần lồng tiếng tự động; tổ chức giáo dục và doanh nghiệp eLearning muốn chuyển giáo trình sang audio; đội ngũ marketing tạo phiên bản nghe của bài viết/blog; nhà phát triển tích hợp API TTS vào ứng dụng, trợ lý ảo, chatbot; đơn vị cần nâng cao khả năng tiếp cận nội dung cho người khiếm thị hoặc người bận rộn.
Cách sử dụng Text To Speech OpenAI
- Đăng nhập và tạo dự án mới cho tài liệu bạn muốn chuyển đổi.
- Tải lên PDF/ePub hoặc dán văn bản cần đọc; kiểm tra bố cục, tiêu đề, chú thích.
- Chọn ngôn ngữ, giọng đọc và phong cách phù hợp nội dung (thuyết minh, kể chuyện, tin tức...).
- Tinh chỉnh tốc độ, cao độ, âm lượng; thêm thẻ SSML để điều khiển ngắt nghỉ, nhấn mạnh, phát âm.
- Nghe thử từng đoạn, hiệu chỉnh từ vựng khó và ký hiệu viết tắt.
- Xuất file MP3/WAV/M4A theo bitrate mong muốn; tùy chọn tách theo chương.
- Tích hợp qua API: gửi văn bản/tài liệu, nhận luồng audio hoặc URL tải về để nhúng vào app/website.
- Quản lý thư viện: gắn thẻ, lưu phiên bản, cập nhật audio khi nội dung thay đổi.
Trường hợp ứng dụng thực tế của Text To Speech OpenAI
Nhà xuất bản chuyển kho eBook sang audiobook để mở rộng kênh doanh thu; trường học và nền tảng eLearning tạo bài giảng audio giúp học mọi lúc, kể cả khi di chuyển; tòa soạn tin tức phát hành bản đọc bài viết hằng ngày; doanh nghiệp chuyển tài liệu nội bộ, SOP, onboarding thành podcast nội bộ; nhà phát triển tích hợp TTS vào trợ lý ảo, IVR hoặc ứng dụng đọc nội dung; marketer tạo phiên bản nghe cho blog/landing page nhằm tăng thời gian ở lại trang và khả năng tiếp cận.
Gói cước và mô hình giá của Text To Speech OpenAI
Nền tảng thường áp dụng mô hình linh hoạt theo mức sử dụng: gói dùng thử miễn phí để trải nghiệm tính năng cơ bản; gói trả phí cá nhân và nhóm với hạn mức ký tự/phút audio cao hơn; tùy chọn doanh nghiệp kèm API, bảo mật nâng cao và hỗ trợ kỹ thuật. Chi phí có thể được tính theo số ký tự, phút âm thanh tạo ra hoặc khối lượng xử lý hàng loạt.
Ưu điểm và nhược điểm của Text To Speech OpenAI
Ưu điểm:
- Giọng đọc tự nhiên, rõ ràng, phù hợp nghe dài.
- Hỗ trợ nhiều định dạng và quy trình từ PDF/eBook tới MP3.
- Tùy chỉnh sâu với SSML, nhiều phong cách giọng.
- API dễ tích hợp, mở rộng tốt cho ứng dụng và quy mô lớn.
- Xử lý nhanh, có xem trước và xuất nhiều định dạng.
Nhược điểm:
- Chất lượng phát âm tên riêng/ký hiệu cần tinh chỉnh thủ công.
- Gói miễn phí có giới hạn ký tự/thời lượng.
- Chi phí có thể tăng theo khối lượng chuyển đổi lớn.
- Phụ thuộc kết nối mạng và chất lượng tài liệu nguồn.
Các câu hỏi thường gặp về Text To Speech OpenAI
-
Câu hỏi:
Text To Speech OpenAI hỗ trợ những định dạng đầu vào và đầu ra nào?
Trả lời:
Hỗ trợ nhập PDF, ePub, Docx và văn bản thuần; xuất MP3, WAV, M4A với tùy chọn bitrate và tách theo chương.
-
Câu hỏi:
Có thể tùy chỉnh tốc độ, cao độ và ngắt nghỉ không?
Trả lời:
Có. Bạn có thể điều chỉnh tham số giọng đọc và dùng SSML để kiểm soát ngắt nghỉ, nhấn mạnh và phát âm.
-
Câu hỏi:
Nền tảng có API để tích hợp vào ứng dụng không?
Trả lời:
Có. API trực quan cho phép gửi văn bản/tệp, nhận audio hoặc luồng phát để nhúng vào website, app, LMS, chatbot.
-
Câu hỏi:
Có hỗ trợ đa ngôn ngữ và nhiều giọng đọc?
Trả lời:
Có. Nền tảng cung cấp nhiều ngôn ngữ và phong cách giọng để phù hợp các ngữ cảnh thuyết minh, kể chuyện hay tin tức.
-
Câu hỏi:
Dữ liệu của tôi có được bảo vệ không?
Trả lời:
Nội dung được xử lý an toàn và bạn có thể quản lý, xóa hoặc cập nhật dự án âm thanh trong thư viện của mình theo nhu cầu.
-
Câu hỏi:
Tôi có thể dùng audio cho mục đích thương mại như podcast hay audiobook bán trả phí?
Trả lời:
Có thể, tùy theo điều khoản sử dụng và giấy phép đi kèm gói cước bạn chọn. Hãy kiểm tra chính sách để đảm bảo tuân thủ.
-
Câu hỏi:
Có giới hạn độ dài tài liệu khi chuyển đổi không?
Trả lời:
Có thể có giới hạn theo gói cước (ký tự hoặc phút audio). Bạn có thể tách chương hoặc dùng xử lý hàng loạt để tối ưu.