
工具資訊
什麼是 wan ai
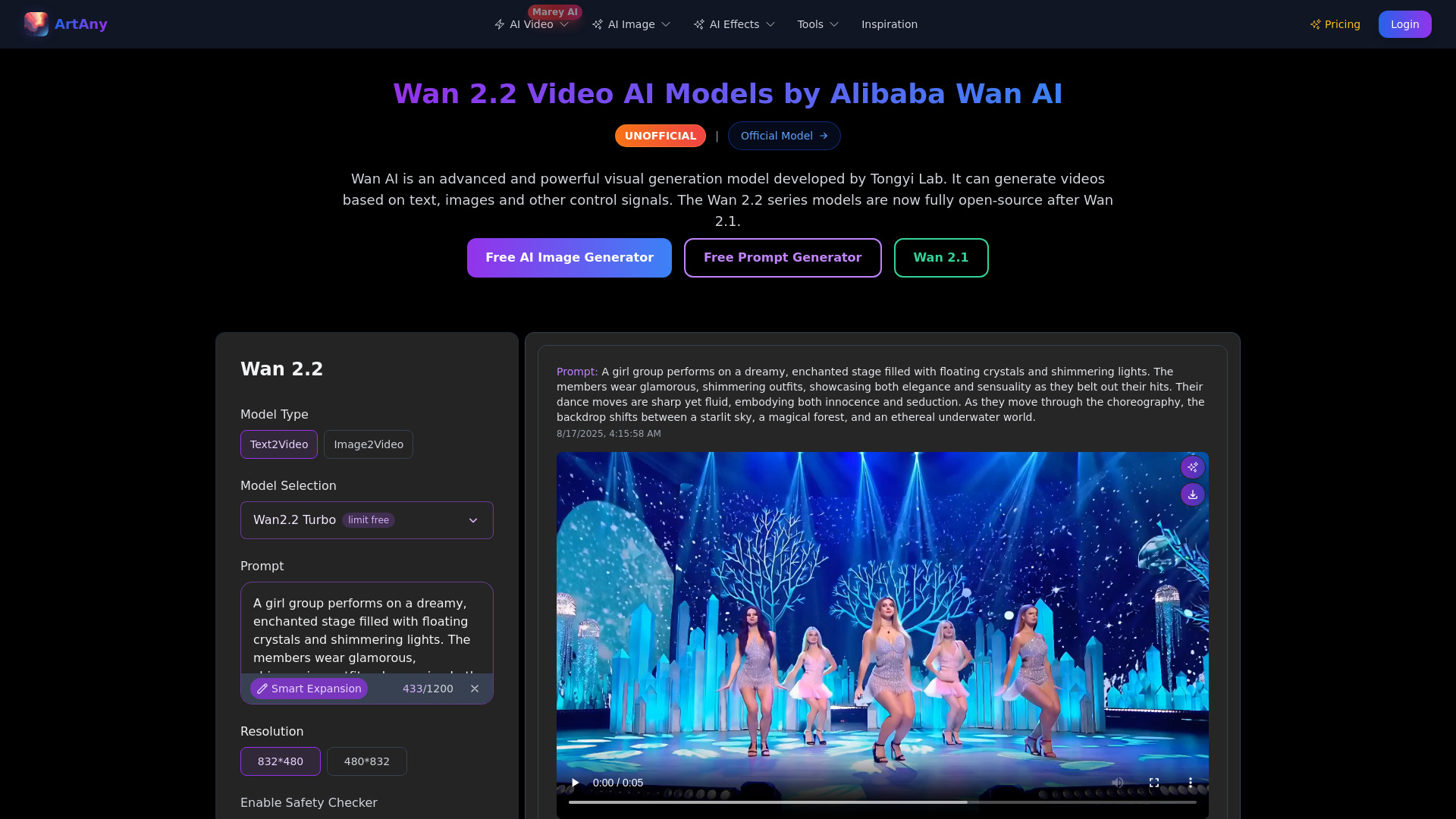
wan ai 是一個聚焦視覺生成的 AI 創作平台,將文字轉圖片、圖片編輯、文字轉影片與圖片轉影片整合於同一介面,協助創作者以更直覺的方式完成從概念到成片的流程。其核心結合先進的生成式模型(包含來自通義實驗室的 Wan 2.2),能夠從文字、圖片與多種控制信號輸出高品質內容,並在複雜運動、物理模擬與鏡頭語言上展現穩定表現。對需要電影級畫質、寫實運動或風格化敘事的場景,wan ai 透過更佳的時序一致性與細節保真度,讓影像邏輯自然、動作可信,並支援中英雙語的視覺文字生成,降低中英文內容跨語系創作的阻力。
相較於傳統後期流程,wan ai 以雲端運算與可視化控制為骨幹,讓使用者能在提示詞、參考圖、遮罩與參數間快速迭代;同時提供可調整的風格、鏡頭運動與場景節奏,縮短從腳本到分鏡再到成片的距離。無論是廣告敘事、產品展示、社群短片、動畫草圖或概念驗證,皆能在平台上完成草擬—生成—微調—導出的完整工作流。對非技術背景的內容團隊而言,wan ai 的介面降低了模型選擇與參數設定的門檻;對專業創作者而言,則提供更細緻的控制維度與一致性的產出品質,成為創意前期探索與最終交付並行的高效工具。
wan ai 主要功能
- 文字轉圖片(Text-to-Image):以自然語言提示快速生成多風格、高解析度圖像,支援主題、構圖與光影控制。
- 圖片編輯(Image Editing):透過參考圖、區域遮罩與提示詞微調,實現換背景、修圖、延展畫布與風格轉換。
- 文字轉影片(Text-to-Video):基於 Wan 2.2 產生高品質影片,兼具複雜運動、物理模擬與鏡頭運動的自然性。
- 圖片轉影片(Image-to-Video):從單張或多張圖片生成具連續性的動態片段,維持角色與場景的一致性。
- 多種控制信號:可結合外部控制條件(如構圖參考、運動節奏或場景約束),提升語義對齊與時序穩定度。
- 視覺文字生成:中英雙語的文字標識、海報標題與界面字樣呈現更清晰,適合品牌素材與宣傳頁視覺。
- 電影級畫質:在光影、材質與景深效果上提供更佳表現,適合敘事短片與高質感商業短影音。
- 使用者友善介面:整合模型選擇、提示詞管理、版本對比與批次導出,支援快速迭代。
wan ai 適用人群
wan ai 適合需要高效率產出視覺內容的創作者與團隊,包括行銷與品牌、公關與活動策劃、社群內容與自媒體、影視製作與動畫前期、遊戲與概念設計、電商與產品視覺、教育培訓與科普傳播等。對希望在短時間完成分鏡提案、產品 Demo、動態視覺測試或多語系素材的使用者,wan ai 能以較低成本完成從草圖到可發布內容的全流程,並透過中英雙語能力支援跨市場溝通。
wan ai 使用步驟
- 建立帳號並登入平台,於個人工作區管理專案與素材。
- 選擇創作模式:文字轉圖片、圖片編輯、文字轉影片或圖片轉影片。
- 撰寫精準提示詞,補充風格、主題、鏡頭語言、節奏與時長等需求;必要時上傳參考圖。
- 選擇模型與參數(如使用 Wan 2.2)、設定解析度、畫面比例、步數與種子值。
- 加入控制信號(如構圖或動作節奏等)以提升語義對齊與時序一致性。
- 開始生成並預覽結果,透過版本對比找出最佳輸出。
- 使用局部編輯或遮罩修飾細節,調整光影、色彩與鏡頭運動。
- 完成後以指定格式與解析度導出,並整理專案檔與版本備份。
wan ai 行業案例
在行銷與品牌溝通中,團隊可用 wan ai 以文字敘述快速生成多版廣告分鏡與短片草案,測試不同視覺語氣與標語樣式,再精修為最終素材。電商可從產品照出發生成動態展示影片,凸顯材質與功能亮點,並同步產出多語系版本服務不同市場。影視與動畫前期可利用文字轉影片完成預視化(Previs),模擬鏡頭走位、光影與場景節奏,降低實拍風險。教育與科普領域則可將抽象概念轉為具體圖像與短動畫,提升學習體驗。遊戲與概念設計團隊可用圖片轉影片驗證角色動作與場景氛圍,快速迭代世界觀與美術方向。
wan ai 優點與缺點
優點:
- 高品質影片生成:在運動連貫、物理模擬與細節保真度上表現穩定。
- 跨模態創作:文字、圖片與控制信號可靈活組合,強化語義對齊。
- 中英雙語視覺文字:標識與字樣呈現清晰,利於品牌與多語系素材。
- 介面友善:提示詞管理、版本對比與批次導出提升迭代效率。
- 電影級畫質與鏡頭語言:適合敘事短片、廣告與高質感短影音。
- 一致性控制:角色、場景與風格在長度與鏡頭切換間更易維持。
缺點:
- 運算成本與時間:高解析度或較長片段生成時間較長,需耐心迭代。
- 學習曲線:仍需掌握提示詞與參數調校,方能穩定獲得理想結果。
- 長序列挑戰:極長時長或大量鏡頭轉換下,一致性可能需多次微調。
- 授權與版權合規:商用前須確認素材來源與使用條款。
- 隱私顧慮:上傳內部素材或人像時需遵循資料與肖像保護規範。
wan ai 熱門問題
-
問:wan ai 是否支援中文與英文的內容與視覺文字生成?
答:支援。平台可用中英雙語進行提示詞撰寫,並能在視覺上生成清晰的中英文文字標識。
-
問:可生成影片的長度與解析度大約是多少?
答:實際可生成的時長與解析度取決於所選模型與參數設定。一般建議先以較短片段與中高解析度驗證,再逐步擴展時長與畫質。
-
問:如何提升視覺中文字與標語的清晰度?
答:在提示詞中明確註記字體風格、位置與對比度,並避免過度複雜的背景;必要時以圖片編輯模式局部加強或分步生成再合成。
-
問:是否能上傳控制信號或參考素材以提升一致性?
答:可以。透過參考圖與多種控制條件,有助於維持角色外觀、鏡頭節奏與場景結構的一致性。
-
問:結果不如預期時,應該如何調整?
答:建議精簡提示詞、調整關鍵參數(如步數、種子、影像比例)、加入更明確參考圖或使用遮罩做局部修正,並以版本對比挑選最佳結果。
-
問:生成內容可否用於商業用途?
答:商用可行性需遵循平台與模型的使用條款,並確保上傳素材具備合法授權。建議在對外發布前再次審閱授權規範。